
Help operator: R provee el operador
?para conocer las opciones y parámetros de las instrucciones. Ej:help("paste")o?paste.
En términos genéricos, todos los elementos que maneja R son objetos: un valor numérico es un objeto, un arreglo es un objeto, una función es un objeto, una base de datos es un objeto, un gráfico es un objeto, …
Para realizar un uso eficiente de R es preciso entender y aprender a manipular bien las distintas clases de objetos que maneja el programa. En esta sección nos vamos a ocupar particulamente de aquellos objetos que R utiliza para representar datos: valores, vectores, matrices, dataframes, series temporales y listas.
R utiliza, de hecho, programación orientada a objetos. Ello significa que una misma función hace cosas distintas según la clase del objeto que recibe como argumento, pudiendo incluso no hacer nada (o producir un error) si se le pasan argumentos de una clase inadecuada.
A modo de ejemplo, veamos cómo la función plot() puede mostrar distintos gráficos según la clase del objeto a representar. Para ello supongamos que el siguiente arreglo representa el número de personas atendidas mensualmente en el servicio de urgencias de un centro de salud durante el año 2000 (datos de enero a diciembre):
atendidos <- c(728,632,596,689,745,865,694,583,657,643,794,887)
atendidos## [1] 728 632 596 689 745 865 694 583 657 643 794 887La asignación de valores a un variable se realiza a través del operador <-. En este caso, la variable atendidos recibe 12 números.
class(atendidos)## [1] "numeric"La función class() nos devuelve la clase del objeto atendidos, que como vemos es numeric. Podemos obtener una representación gráfica de este arreglo simplemente mediante:
plot(atendidos)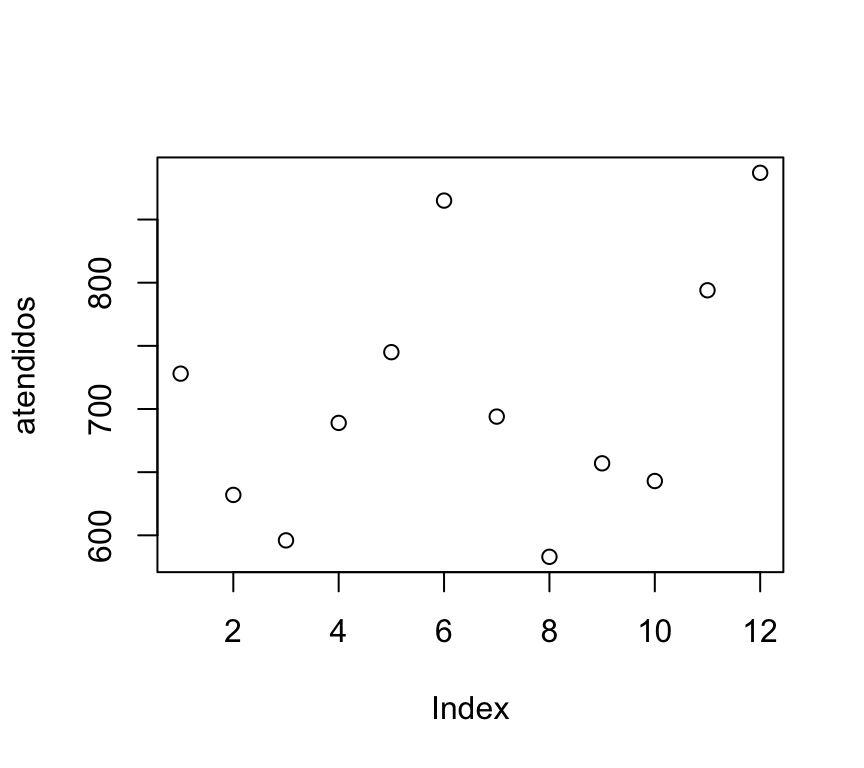
Ahora convertimos estos datos en serie temporal mediante la función ts(), indicando que esta serie comienza en enero del año 2009 y que tiene una frecuencia de 12 observaciones por año (esto es, una por mes):
atendidos2 <- ts(atendidos,frequency=12,start=c(2009,1))
atendidos2## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 2009 728 632 596 689 745 865 694 583 657 643 794 887class(atendidos2)## [1] "ts"Como podemos ver, la clase del objeto atendidos2 es ts (time series). Podemos comprobar que si aplicamos la misma función plot() a atendidos2, el gráfico obtenido es distinto que cuando se aplica a atendidos, aún cuando los datos sean exactamente los mismos:
plot(atendidos2)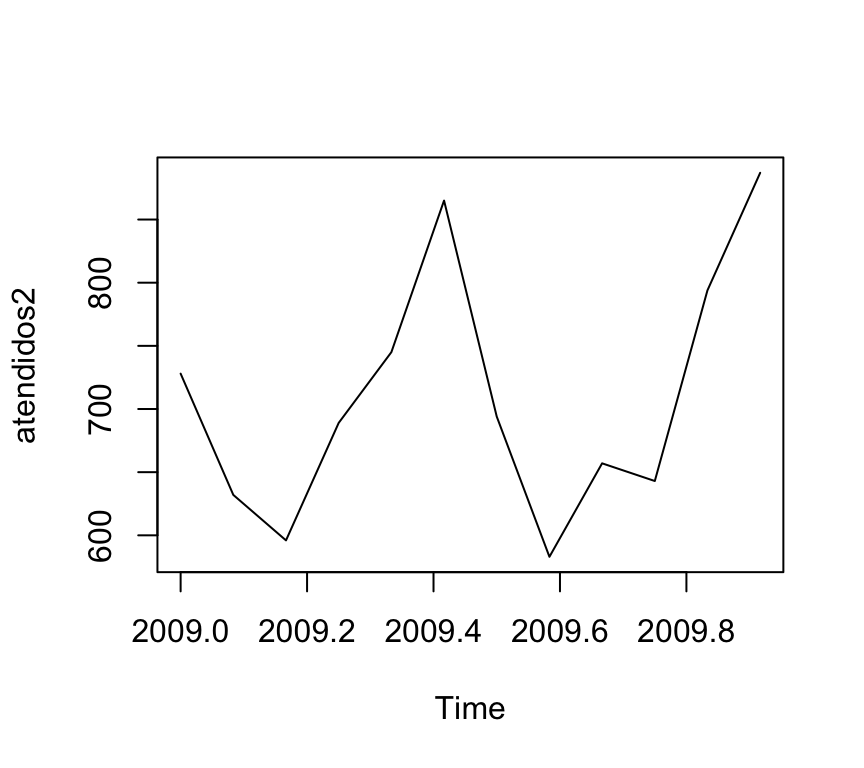
Una de las grandes potencialidades que tiene R es la utilización de paquetes (o librerías). R tiene una serie de comandos que se cargan por default. Sin embargo, hay una gran cantidad de funcionalidades que se deben cargar a través de paquetes.
Un paquete (package) es una colección de funciones, datos y código R que se almacenan en una carpeta conforme a una estructura bien definida, fácilmente accesible para R. En la web de R se puede consultar la lista de paquetes disponibles.
Puede haber paquetes: * Instalados en R pero que no están en memoria. Son paquetes que se han descargado junto con la instalación de R pero que, para su uso, se requiere cargarlos en memoria. Ejemplo:
library("plyr")if (!is.element("readr", installed.packages()[,1])){
install.packages("readr", repos = "http://mirror.fcaglp.unlp.edu.ar/CRAN/")
}
library("readr")Veamos un ejemplo:
R posee, en memoria, una tabla-ejemplo llamada airquality. Se puede ver por consola escribiendo su nombre+Enter. Si quisieramos cambiar el signo de los valores de la columna “Ozone”, podríamos cargar el paquete “plyr” que contiene la función “mutate()”. Este paquete ya está instalado pero se requiere cargarlo en memoria. Para eso vamos a cargar en memoria el paquete:
library("plyr")Ahora que el paquete está en memoria, podemos ejecutar la instrucción:
head(mutate(airquality, Ozone = -Ozone))## Ozone Solar.R Wind Temp Month Day
## 1 -41 190 7.4 67 5 1
## 2 -36 118 8.0 72 5 2
## 3 -12 149 12.6 74 5 3
## 4 -18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 -28 NA 14.9 66 5 6Y podremos ver por consola cómo combió el signo.
En el area File/Plots/Packages/Help/Viewer:, si haces click en “Packages” podrás ver un listado de paquetes, y qué paquetes tienes instalados. Puedes instalar paquetes haciendo click en “Install”.
En este link puedes ver un listado completo de paquetes disponibles.
R distingue los siguientes tipos de variables:
a <- 2.15b <- 3
c <- as.integer(a) # para transformar un variable float en entera. Un factor es una variable categórica con un número finito de valores o niveles. En R los factores se utilizan habitualmente para realizar clasificaciones de los datos, estableciendo su pertenencia a los grupos o categorías determinados por los niveles del factor.
Los factores juegan un papel muy importante en la elaboración de modelos estadísticos. En particular, los modelos lineales pueden dar resultados muy diferentes según que una variable se declare como numérica o como factor.
Los niveles de un factor puede estar codificados como valores numéricos o como caracteres. Independientemente de que el factor sea numérico o carácter, sus valores son siempre almacenados internamente por R como números enteros, con lo que se consigue economizar memoria.
Consideremos el siguiente ejemplo. La variable:
sexo <- c("M", "H", "M", "M", "M", "H", "M", "M", "H", "H")
sexo## [1] "M" "H" "M" "M" "M" "H" "M" "M" "H" "H"puede ser considerada un factor, ya que establece para cada sujeto su pertenencia a una de las dos categorías “Hombre”" o “Mujer”. Para que R reconozca al sexo como factor, una vez introducidos los datos utilizamos la función:
sexo <- factor(sexo)
sexo## [1] M H M M M H M M H H
## Levels: H Mcon lo que hemos convertido sexo en un factor con dos niveles M y H. En muchos casos, los niveles del factor son poco ilustrativos de su significado. La siguiente sintaxis especifica explícitamente los niveles del factor (levels) y asigna etiquetas (labels) a cada uno de ellos:
sexo <- factor(sexo,levels=c("H","M"),labels=c("Hombre","Mujer"))
sexo## [1] Mujer Hombre Mujer Mujer Mujer Hombre Mujer Mujer Hombre Hombre
## Levels: Hombre MujerEstas etiquetas aparecerán en los resultados de los procedimientos estadísticos donde apareza el factor, aclarando su significado. Por ejemplo, si pedimos a R que nos construya la tabla de frecuencias de sexos, en lugar de H o M nos mostrará los términos “Hombre”" o “Mujer”:
table(sexo)## sexo
## Hombre Mujer
## 4 6Hay alguna funciones en R que requieren que la variable de entrada sea necesariamente un factor (aún cuando la variable esté codificada numéricamente). Para ello basta recodificar la variable original como factor. Por ejemplo, supongamos que se ha registrado la producción de tres máquinas (identificadas como 27, 32 y 55) durante cinco días sucesivos, dando como resultado los siguientes datos:
produccion=c(120,100,132,112,95,164,172,183,155,176,110,115,122,108,120)
maquina=c(27,27,27,27,27,32,32,32,32,32,55,55,55,55,55)
dia=c(1,2,3,4,5,1,2,3,4,5,1,2,3,4,5)
cbind(maquina,dia,produccion)## maquina dia produccion
## [1,] 27 1 120
## [2,] 27 2 100
## [3,] 27 3 132
## [4,] 27 4 112
## [5,] 27 5 95
## [6,] 32 1 164
## [7,] 32 2 172
## [8,] 32 3 183
## [9,] 32 4 155
## [10,] 32 5 176
## [11,] 55 1 110
## [12,] 55 2 115
## [13,] 55 3 122
## [14,] 55 4 108
## [15,] 55 5 120Si se pretende evaluar la producción de estas tres máquinas a lo largo de estos días, es evidente que sus números de identificación (27, 32 y 55) son simples etiquetas sin que su valor intrínseco tenga ningún sentido en el problema. En este caso resulta razonable (y, como veremos, en el ajuste de modelos de análisis de la varianza es además necesario) convertir esta variable en factor. Para ello simplemente ejecutamos:
maquina=factor(maquina)
maquina## [1] 27 27 27 27 27 32 32 32 32 32 55 55 55 55 55
## Levels: 27 32 55Un factor puede convertirse en variable numérica mediante la función as.numeric(). Ahora bien, dichas conversiones deben realizarse con cierta precaución. Así por ejemplo, si en el caso anterior aplicamos la función as.numeric() al factor maquina obtenemos:
as.numeric(maquina) ## [1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3¡No se han recuperado los valores originales 27, 32 y 55!. Lo que ocurre en este caso es que R muestra la codificación interna de los niveles del factor (habitualmente valores enteros ordenados desde 1 hasta el número total de niveles). Si quisiéramos recuperar los valores numéricos originales de la variable maquina debemos primero convertirla en carácter, y a continuación en numérica:
as.numeric(as.character(maquina))## [1] 27 27 27 27 27 32 32 32 32 32 55 55 55 55 55Las variables lógicas constituyen un tipo particular de factor en R, que se caracteriza por tomar sólo dos valores: TRUE o FALSE codificados, respectivamente, como 1 y 0. Es posible construir condiciones lógicas utilizando los operadores ‘y’ (&), ‘o’ (|) y ‘no’ (!).
La comparación de valores se lleva a cabo mediante == (‘es igual a’) y != (‘es distinto de’).
ATENCIÓN: No debe confundirse el operador de asignación = con el de comparación ==.
Veamos algunos ejemplos:
a <- 2
b <- 4
a==b # ¿es a igual a b?## [1] FALSEa!=b # ¿es a distinto de b?## [1] TRUE(a<3)&(b<5) # ¿es a menor que 3 y b menor que 3?## [1] TRUE(a<1)|(b<3) # ¿es a menor que 1 o b menor que 3?## [1] FALSEFunciones any() y all()
Las funciones any(x) y all(x) determinan, respectivamente, si alguno o todos los elementos de x son TRUE:
any(c(a==2, a==3, a==4))## [1] TRUEany(c(a==3, a==4, a==5, a==6))## [1] FALSEall(c(a==2, b==4, 2<3))## [1] TRUESe pueden agrupar varios elementos de la misma clase para formar un vector mediante el comando de concatenación c(). Así, podemos guardar las edades de 10 personas de una muestra en la variable edad mediante:
edad <- c(22, 34, 29, 25, 30, 33, 31, 27, 25, 25)
edad## [1] 22 34 29 25 30 33 31 27 25 25class(edad)## [1] "numeric"La función length() devuelve la longitud (número de elementos) del vector:
x <- c(1,4,5,2,4,5,4,3,2,2,3,2,2,4,4,5,5,6,6,7)
length(x)## [1] 20Importante: La longitud de un vector es fija!
Es posible acceder al valor que ocupa la posición k dentro de un vector x refiriéndonos a él como x[k]. Así, por ejemplo, podemos ver el contenido del tercer y quinto valores del vector edad:
edad <- c(22, 34, 29, 25, 30, 33, 31, 27, 25, 25)
edad[3]## [1] 29edad[5]## [1] 30:Si deseamos asignar a una variable una sucesión de valores consecutivos podemos utilizar el operador :. Así para asignar a la variable x los valores de 1 a 10 procederíamos del siguiente modo:
x <- 1:10
x## [1] 1 2 3 4 5 6 7 8 9 10Podemos construir secuencias de números más complejas mediante la función seq():
Sucesión de valores de 1 a 20 de 2 en 2:
x <- seq(1,20,by=2)
x## [1] 1 3 5 7 9 11 13 15 17 19Sucesión de 8 valores equiespaciados entre 1 y 20:
y <- seq(1,20,length=8)
y## [1] 1.000000 3.714286 6.428571 9.142857 11.857143 14.571429 17.285714 20.000000Podemos acceder también simultáneamente a varios valores dentro de un vector. Por ejemplo, si deseamos ver del segundo al quinto de los valores observados en la variable edad:
edad[2:5]## [1] 34 29 25 30Y si quisiéramos ver sólo los valores primero, tercero y séptimo:
edad[c(1,3,7)]## [1] 22 29 31La función %in% permite determinar si uno o varios valores están contenidos en un vector:
x <- 1:10
a <- 2
a %in% x## [1] TRUEb <- c(6,8,14,2,15)
b %in% x## [1] TRUE TRUE FALSE TRUE FALSELa función which() nos da las posiciones, dentro de un vector, de los valores que cumplen cierta condición. Por ejemplo, si definimos:
edad <- c(22, 34, 29, 25, 30, 33, 31, 27, 25, 25)La siguiente función nos devuelve las posiciones de los valores de este arreglo que son mayores que 25:
which(edad>25)## [1] 2 3 5 6 7 8Esto es: los valores del vector edad mayores que 25 son los que ocupan las posiciones 2, 3, 5, 6, 7 y 8.
Podemos asignar estas posiciones a una nueva variable:
mayores25 <- which(edad>25)y utilizarla para mostrar cuáles son concretamente esos valores mediante:
edad[mayores25]## [1] 34 29 30 33 31 27Esta expresión puede simplificarse, si no utilizamos which():
edad[edad>25]## [1] 34 29 30 33 31 27La operación which() es aplicable también a otras estructuras de datos en R. Es, en efecto, un operador potente para la ciencia de datos.
Se puede realizar también la selección de valores de un vector condicionando por los valores de otro vector Por ejemplo, si las diez edades del ejemplo anterior corresponden a personas cuyo sexo viene dado por:
sexo <- c("M","H","H","M","M","H","M","M","H","H")podríamos seleccionar la edad de las mujeres simplemente mediante:
edad[sexo=="M"]## [1] 22 25 30 31 27unique()Es frecuente que, dado un conjunto de datos, nos interese solamente conocer los valores, sin importar su repetición en el conjunto:
unique(sexo)## [1] "M" "H"table()Si quisieramos conocer cuántas repeticiones tiene cada elemento se puede utilizar:
table(edad)## edad
## 22 25 27 29 30 31 33 34
## 1 3 1 1 1 1 1 1Si x e y son dos vectores de la misma dimensión, las operaciones elementales se realizan término a término (característica que se conoce como aritmética vectorial):
x <- seq(2,20,by=2) # Números pares entre 2 y 20
x## [1] 2 4 6 8 10 12 14 16 18 20y <- seq(1,20,by=2) # Números impares entre 1 y 20
y## [1] 1 3 5 7 9 11 13 15 17 19x+y## [1] 3 7 11 15 19 23 27 31 35 39x-y## [1] 1 1 1 1 1 1 1 1 1 1x*y## [1] 2 12 30 56 90 132 182 240 306 380x/y## [1] 2.000000 1.333333 1.200000 1.142857 1.111111 1.090909 1.076923 1.066667 1.058824 1.052632character.En R se pueden declarar vectores alfanuméricos (o de clase carácter):
letras <- c("a","b","c","d")
class(letras)## [1] "character"paste(): esta función “pega” (o concatena) variables de clase character; la opción sep indica el símbolo que separa los valores que se han pegado; en caso de que no se quiera dejar ningún símbolo de separación, debe usarse sep="":paste("A","B",sep="-")## [1] "A-B"Podemos pegar vectores (se pegarán término a término: primer valor con primer valor, segundo con segundo, etc.)
codigos <- paste(c("A", "B"), 2:3, sep = "")
codigos## [1] "A2" "B3"codigos <- paste(c("A", "B"), 2:3, sep = ".")
codigos## [1] "A.2" "B.3"Obsérvese, que con la opción sep se obtiene como resultado un vector de la misma longitud que los vectores que se pegan.
Cuando se utiliza paste() sobre un único vector con la opción collapse, se “pegan” todos los términos del arreglo en un único valor:
paste(c("una", "frase", "simple"), collapse = " ")## [1] "una frase simple"La función substr(x,n1,n2) selecciona los caracteres de x entre las posiciones n1 y n2. También permite realizar asignaciones:
substr("abcdef", 2, 4)## [1] "bcd"x <- "ABCDEF"
x## [1] "ABCDEF"substr(x, 3, 5) <- c("uv")
x## [1] "ABuvEF"Tarea:
Utiliza la ayuda de R para averiguar la utilidad de las funciones nchar, grep, match, tolower, toupper.
stringrEl paquete stringr ofrece funciones para el manejo de caracteres. Como este paquete no viene con R, hay que instalarlo y cargarlo en memoria:
if (!is.element("stringr", installed.packages()[,1])){
install.packages("stringr")
}
library(stringr)La siguiente tabla contiene algunas funciones de stringr para operar sobre caracteres:
| Function | Description | Similar to |
|---|---|---|
str_c() |
concatenación de string | paste() |
str_length() |
número de caracteres | nchar() |
str_sub() |
extraer substrings | substring() |
str_dup() |
duplicar caracterires | none |
str_trim() |
remover espacios blancos (inicio y fin) | none |
En R las matrices son vectores multidimensionales. Heredan las propiedades de vectores y hay varias maneras de definirlas. Si es pequeña podemos utilizar la siguiente sintaxis:
A <- matrix(nrow=3,ncol=3, c(1,2,3,4,5,6,7,8,9), byrow=TRUE)Con el argumento nrow hemos indicado el número de filas de nuestra matriz, con ncol el número de columnas. A continuación hemos puesto los valores que forman la matriz (los valores del 1 al 9), y le hemos pedido a R que use esos valores para rellenar la matriz A por filas `(byrow=TRUE)´. La matriz A así construida es:
A## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 9Tarea:
Comprueba cómo queda la matriz si se utiliza byrow=FALSE.
Se pueden seleccionar partes de una matriz utilizando los índices de posición [fila, columna] entre corchetes. El siguiente ejemplo ilustra la forma de hacerlo:
A[2,3] # Se selecciona el valor de la fila 2, columna 3## [1] 6A[2,] # Se selecciona la fila 2 completa## [1] 4 5 6A[,3] # Se selecciona la columna 3 completa## [1] 3 6 9A[1,2:3] # Se seleccionan el segundo y tercer valor de la fila 1## [1] 2 3Tarea:
Si disponemos de varios arreglos de la misma longitud que queremos utilizar como filas (o columnas) de una matriz, podemos utilizar la función rbind() para unirlos por filas, o la función cbind() para unirlos por columnas, como vemos en el siguiente ejemplo:
vector1 = c(1,2,3,4)
vector2 = c(5,6,7,8)
vector3 = c(9,10,11,12)
M1 = cbind(vector1,vector2,vector3) # Unimos por columnas
M1 ## vector1 vector2 vector3
## [1,] 1 5 9
## [2,] 2 6 10
## [3,] 3 7 11
## [4,] 4 8 12Tarea:
Crea una matriz M2 con los arreglos anteriores unidos por filas mediante rbind(). Compara el resultado con la matriz M1 anterior.
La función diag() extrae la diagonal principal de una matriz:
diag(A)## [1] 1 5 9Tarea:
%*%.El término “dataframe” es difícil de traducir al castellano. Podría traducirse como Hoja de datos o Marco de datos. Los dataframes son una clase de objetos especial en R. Normalmente, cuando se realiza un estudio estadístico sobre los sujetos u objetos de una muestra, la información se organiza precisamente en un dataframe: una hoja de datos, en los que cada fila corresponde a un sujeto y cada columna a una variable. La estructura de un data.frame es muy similar a la de una matriz. La diferencia es que una matriz sólo admite valores numéricos, mientras que en un dataframe podemos incluir también datos alfanuméricos.
El siguiente ejemplo nos muestra como crear un data.frame a partir de los datos recogidos sobre una muestra de 10 personas, para cada una de las cuales se ha registrado su edad, sexo y tiempo en minutos que estuvo hablando por teléfono el día antes de la encuesta:
edad <- c(22, 34, 29, 25, 30, 33, 31, 27, 25, 25)
tiempo <- c(14.21, 10.36, 11.89, 13.81, 12.03, 10.99, 12.48, 13.37, 12.29, 11.92)
sexo <- c("M","H","H","M","M","H","M","M","H","H")
misDatos <- data.frame(edad,tiempo,sexo)
misDatos## edad tiempo sexo
## 1 22 14.21 M
## 2 34 10.36 H
## 3 29 11.89 H
## 4 25 13.81 M
## 5 30 12.03 M
## 6 33 10.99 H
## 7 31 12.48 M
## 8 27 13.37 M
## 9 25 12.29 H
## 10 25 11.92 Hstr(misDatos) # Estructura de 'misDatos'## 'data.frame': 10 obs. of 3 variables:
## $ edad : num 22 34 29 25 30 33 31 27 25 25
## $ tiempo: num 14.2 10.4 11.9 13.8 12 ...
## $ sexo : chr "M" "H" "H" "M" ...names(misDatos) # Nombre de las variables contenidas en 'misDatos'## [1] "edad" "tiempo" "sexo"En este ejemplo hemos creado un data.frame llamado misDatos que contiene a las tres variables edad, tiempo y sexo. La función str() nos muestra la estructura de este objeto, confirmándonos que es un data.frame de tres variables con 10 observaciones cada una. Nos informa además de que las dos primeras variables son numéricas y la tercera, el sexo, es un factor con dos valores, “H” y “M”. La función names() por su parte, nos devuelve los nombres de las variables contenidas en misDatos.
Cuando desde R se leen datos situados en un fichero externo (un fichero de texto, una hoja excel, un archivo de datos de SPSS,…), estos datos se importan en un data.frame.
str(M1)## num [1:4, 1:3] 1 2 3 4 5 6 7 8 9 10 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:3] "vector1" "vector2" "vector3"M2<-as.data.frame(M1)
str(M2)## 'data.frame': 4 obs. of 3 variables:
## $ vector1: num 1 2 3 4
## $ vector2: num 5 6 7 8
## $ vector3: num 9 10 11 12El acceso a los datos que se encuentran en un data.frame es muy similar al acceso a los datos de una matriz que ya vimos en la sección anterior. Sin embargo, para los data.frames R dispone de algunas funciones que facilitan la tarea de seleccionar o filtrar datos. Así por ejemplo, si queremos ver sólo los datos de los sujetos (filas) 3 a 6, escribiríamos:
misDatos[3:6,] #Mostrar solo las personas de las filas 3 a 6.## edad tiempo sexo
## 3 29 11.89 H
## 4 25 13.81 M
## 5 30 12.03 M
## 6 33 10.99 HmisDatos[,1] #Mostrar solo la edad de las personas.## [1] 22 34 29 25 30 33 31 27 25 25misDatos$edad #Otra manera de mostrar solo la edad de las personas. ## [1] 22 34 29 25 30 33 31 27 25 25misDatos[,"edad"] #Otra manera de mostrar solo la edad de las personas.## [1] 22 34 29 25 30 33 31 27 25 25Tarea:
medidas <- data.frame(longitud=c(6,4,7), peso=c(240,326,315), diametro=c(8,9,9))
with(medidas,{
volumen <- longitud*pi*(diametro/2)^2 # Calcula el volumen de los objetos
densidad <- peso/volumen # Calcula su densidad
densidad # Muestra los valores de densidad
})## [1] 0.7957747 1.2810990 0.7073553hombres <- subset(misDatos,sexo=="H")
hombres## edad tiempo sexo
## 2 34 10.36 H
## 3 29 11.89 H
## 6 33 10.99 H
## 9 25 12.29 H
## 10 25 11.92 Hmujeres <- subset(misDatos,sexo=="M")
mujeres## edad tiempo sexo
## 1 22 14.21 M
## 4 25 13.81 M
## 5 30 12.03 M
## 7 31 12.48 M
## 8 27 13.37 Mmayores <- subset(misDatos,sexo=="H" & edad>30)
mayores## edad tiempo sexo
## 2 34 10.36 H
## 6 33 10.99 Hjov_habladores <- subset(misDatos,sexo=="H" & edad<30 & tiempo>12)
jov_habladores## edad tiempo sexo
## 9 25 12.29 Hextremos <- subset(misDatos,edad<25|edad>30)
extremos## edad tiempo sexo
## 1 22 14.21 M
## 2 34 10.36 H
## 6 33 10.99 H
## 7 31 12.48 Mhombres <- subset(misDatos,sexo=="H", select=c(edad, tiempo))
hombres## edad tiempo
## 2 34 10.36
## 3 29 11.89
## 6 33 10.99
## 9 25 12.29
## 10 25 11.92merge()Como ya comentamos en la sección de matrices, rbind (acrónimo de rowbind, pegar por filas) permite combinar arreglos (o matrices o data.frames) “uno debajo del otro”:
animales1 <- data.frame(animal=c("vaca","perro","rana","lagarto","mosca","jilguero"),
clase=c("mamífero","mamífero","anfibio","reptil","insecto","ave"))
animales2 <- data.frame(animal=c("atún", "cocodrilo", "gato","rana"), clase=c("pez", "reptil", "mamífero","anfibio"))
animales3 <- rbind(animales1,animales2)El comando rbind no controla la posible aparición de casos repetidos en los dos dataframes (podemos comprobar que la rana está repetida en el dataframe ‘animales3’). La función merge() evita este problema; utilizando la opción all=TRUE ó all=FALSE (valor por defecto) se consigue que se muestren todos los datos de ambos data.frames, o sólo aquellos que son comunes a ambos:
animales4=merge(animales1,animales2)
animales5=merge(animales1,animales2,all=TRUE)Si los data.frames tienen estructura distinta, pero contienen variables en común que permiten identificar unívocamente a los mismos objetos en ambos conjuntos, también podemos combinarlos mediante merge():
superficieAnimales=data.frame(animal=c("perro","tortuga","jilguero",
"cocodrilo","vaca","lagarto","sardina"),
superficie=c("pelo","placas óseas","plumas",
"escamas","pelo","escamas","escamas"))
merge(animales3,superficieAnimales) # Muestra sólo los animales comunes a ambos dataframes## animal clase superficie
## 1 cocodrilo reptil escamas
## 2 jilguero ave plumas
## 3 lagarto reptil escamas
## 4 perro mamífero pelo
## 5 vaca mamífero pelomerge(animales3,superficieAnimales, all.x=TRUE) # Muestra todos los animales del primer dataframe.## animal clase superficie
## 1 atún pez <NA>
## 2 cocodrilo reptil escamas
## 3 gato mamífero <NA>
## 4 jilguero ave plumas
## 5 lagarto reptil escamas
## 6 mosca insecto <NA>
## 7 perro mamífero pelo
## 8 rana anfibio <NA>
## 9 rana anfibio <NA>
## 10 vaca mamífero pelomerge(animales3,superficieAnimales, all.y=TRUE) # Muestra todos los animales del segundo dataframe.## animal clase superficie
## 1 cocodrilo reptil escamas
## 2 jilguero ave plumas
## 3 lagarto reptil escamas
## 4 perro mamífero pelo
## 5 sardina <NA> escamas
## 6 tortuga <NA> placas óseas
## 7 vaca mamífero peloPara ordenar un dataframe hemos de aplicar la función order() al elemento o elementos por el que queramos ordenar, y utilizar el resultado de esta función como índice del data.frame.
Por ejemplo, si queremos ordenar el dataframe animales1 por orden alfabético de animales, haríamos:
ordenacion <- order(animales1$animal) # Posiciones dentro del dataframe 'animales1' de los animales ordenados alfabéticamente
animales1 <- animales1[ordenacion,] # Se reordenan las filas del dataframe animales1
animales1 <- animales1[order(animales1$animal),] # lo mismo pero en una sola línea de código.Si queremos ordenar nuestro primer data.frame (misDatos) primero por edad y luego por tiempo utilizando el celular:
misDatos <- misDatos[order(misDatos$edad,misDatos$tiempo),]table()Ya utilizamos la función table() en arreglos. Lo hicimos para saber cuántas repeticiones tenía cada elemento de un arreglo. Esta función también se puede usar en matrices o data.frames:
table(misDatos[,"sexo"])##
## H M
## 5 5table(misDatos[,c("sexo", "edad")])## edad
## sexo 22 25 27 29 30 31 33 34
## H 0 2 0 1 0 0 1 1
## M 1 1 1 0 1 1 0 0Una lista, en R, se puede ver como un contenedor de objetos que pueden ser de cualquier clase: números, arreglos, matrices, funciones, data.frames, incluso otras listas. Una lista puede contener a la vez otros objetos, que pueden ser además de distintas dimensiones.
Por ejemplo, podemos crear una lista que contenga el data.frame misDatos, la matriz A, la matriz M, el arreglo x <- c(1,2,3,4) y la constante e <- exp(1):
A <- matrix(1:9,nrow=3)
M <- matrix(1,4,nrow=2)
MiLista <- list(misDatos,A,M=M,x=c(1,2,3,4),e=exp(1))Obsérvese a continuación cómo podemos acceder a los distintos elementos de la lista. Póngase especial atención a lo que ocurre con los elementos misDatos y A, cuyo nombre no se utilizó explícitamente en la declaración de la lista:
MiLista$misDatos## NULLMiLista[[1]]## edad tiempo sexo
## 1 22 14.21 M
## 10 25 11.92 H
## 9 25 12.29 H
## 4 25 13.81 M
## 8 27 13.37 M
## 3 29 11.89 H
## 5 30 12.03 M
## 7 31 12.48 M
## 6 33 10.99 H
## 2 34 10.36 HMiLista$A## NULLMiLista[[2]]## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9MiLista$M## [,1] [,2] [,3] [,4]
## [1,] 1 1 1 1
## [2,] 1 1 1 1MiLista$x## [1] 1 2 3 4Como vemos, para acceder a los objetos que forman parte de una lista, basta con añadir su nombre a continuación del de la lista, separados por el símbolo $, o bien con el índice de posición dentro de la lista con doble corchete [[]]. Nótese que los objetos misDatos y A no tienen nombre dentro de la lista, por lo que hemos de referirnos a ellos como MiLista[[1]] o MiLista[[2]]. Sin embargo, el objeto M sí que tiene nombre. Para que un objeto dentro de una lista tenga nombre, éste debe declararse explícitamente en la construcción de la lista, tal como se hizo con M, x o `e.
R utiliza las listas, sobre, todo como salida de los distintos procedimientos estadísticos. Así, por ejemplo, al realizar un contraste de medias de dos poblaciones, R calcula, entre otras cosas, la diferencia de medias muestrales, el valor del estadístico de contraste, el p-valor del test y el intervalo de confianza para la diferencia observada. Todos estos términos forman parte de una lista. La sintaxis para comparar, por ejemplo, el tiempo medio de uso del celular entre hombres y mujeres a partir de nuestros datos sería:
t.test(tiempo~sexo, data=misDatos)##
## Welch Two Sample t-test
##
## data: tiempo by sexo
## t = -3.1333, df = 7.8535, p-value = 0.01427
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -2.9378177 -0.4421823
## sample estimates:
## mean in group H mean in group M
## 11.49 13.18Si guardamos el resultado de este contraste en el objeto contraste, podemos observar que tiene estructura de lista:
contraste <- t.test(tiempo~sexo, data=misDatos)
str(contraste)## List of 10
## $ statistic : Named num -3.13
## ..- attr(*, "names")= chr "t"
## $ parameter : Named num 7.85
## ..- attr(*, "names")= chr "df"
## $ p.value : num 0.0143
## $ conf.int : num [1:2] -2.938 -0.442
## ..- attr(*, "conf.level")= num 0.95
## $ estimate : Named num [1:2] 11.5 13.2
## ..- attr(*, "names")= chr [1:2] "mean in group H" "mean in group M"
## $ null.value : Named num 0
## ..- attr(*, "names")= chr "difference in means"
## $ stderr : num 0.539
## $ alternative: chr "two.sided"
## $ method : chr "Welch Two Sample t-test"
## $ data.name : chr "tiempo by sexo"
## - attr(*, "class")= chr "htest"Si deseamos extraer, por ejemplo, solo el intervalo de confianza de la lista anterior nos bastaría con ejecutar:
contraste$conf.int## [1] -2.9378177 -0.4421823
## attr(,"conf.level")
## [1] 0.95En R es posible “forzar” (“coerce”) la conversión de una clase de datos en otra, mediante comandos de la forma as.class. Por ejemplo:
x="1"
x## [1] "1"class(x)## [1] "character"y=as.integer(x)
y## [1] 1class(x)## [1] "character"z=as.character(y)
z## [1] "1"class(z)## [1] "character"R tiene un manejo muy potente de operaciones entre tipos primitivos <-> arreglos <-> matrices. Veamos unos ejemplos:
a <- c(1,2,3,4)
# operaciones entre escalares y arreglos:
a + 5## [1] 6 7 8 9a*4## [1] 4 8 12 16b <- a - 10
sqrt(a)## [1] 1.000000 1.414214 1.732051 2.000000log(a)## [1] 0.0000000 0.6931472 1.0986123 1.3862944# operaciones sobre arreglos:
c <- sort(a)
d <- sort(a,decreasing = TRUE)
min(a)## [1] 1e <- c(TRUE,FALSE,FALSE,TRUE)
a[e]## [1] 1 4a <- c(10,20,30,40,NA)
sum(a)## [1] NAsum(a, na.rm = TRUE) # el parámetro na.rm = TRUE significa que no se deben tener en cuenta los valores NA. ## [1] 100is.na(a)## [1] FALSE FALSE FALSE FALSE TRUEa[!is.na(a)]## [1] 10 20 30 40b <- a[!is.na(a)]
b <- a[a<6]R cuenta con un catálogo muy completo de funciones matemáticas. Por citar unas pocas: logaritmo neperiano (log), exponencial (exp), seno (sin), coseno (cos), valor absoluto (abs), parte entera (floor), redondeo (round). Cuando una función se aplica a un arreglo, se aplica a todos y cada uno de sus elementos:
x <- 1
x^2## [1] 1log(x)## [1] 03*x## [1] 31/exp(x)## [1] 0.3678794Instrucciones simples y útiles:
# cargar números reales hasta que se presione Enter, y guardarlos en la variable a:
a<-scan(what=double(0))Otros comandos:
Sugerimos que explores, por tu cuenta, los siguientes comandos: help(repeat), help(break), help(next), help(switch).
x <- 0.1
if( x < 0.2)
{
x <- x + 1
cat("Incremento el número!\n")
}
if( x == 0)
{
cat("El número vale 0!\n")
} else {
cat("El número es distinto a 0\n")
}
x# op1:
for(cont in (1:10)){
print(paste0("Iteración número: ",cont))
}
# op2:
for (cont in seq(0,1,by=0.3)){
print(paste0("Iteración número: ",cont))
}
# op3:
x <- c(1,2,4,8,16)
for (loop in x)
{
cat("Valor de la iteración: ",loop,"\n");
}Probar el siguiente programa y explicar qué operación realiza:
lupe <- 1
x <- 1
while(x < 4)
{
x <- rnorm(1,mean=2,sd=3)
cat("trying this value: ",x," (",lupe," times in loop)\n");
lupe <- lupe + 1
}applyLas funciones apply(), sapply(), lapply() y tapply() resultan extremadamente útiles también para evitar bucles. Su objetivo fundamental es aplicar (de ahí el nombre) una función a todos los elementos de un objeto. En realidad son funciones que de alguna manera ejecutan un bucle, pero este bucle se ejecuta en código compilado lo que hace que sea más rápido que utilizar los comandos for, repeat o while que siempre deben ser interpretados. No siempre será posible sustituir un bucle por una función de la familia apply, pero cuando lo sea, su utilización es muy ventajosa.
Concretamente:
apply(M,i,fun): si i vale 1, aplica la función fun a todas las filas de la matriz M; si `i vale 2, la aplica a las columnas.Por ejemplo, supongamos que queremos calcular la suma de los cuadrados de cada fila y de cada columna de una matriz de términos aleatorios:
A = matrix(runif(50),nrow=10) # Matriz de dimensión 10x10 cuyos elementos son valores
# aleatorios con distribución uniforme en (0,1)
A## [,1] [,2] [,3] [,4] [,5]
## [1,] 0.1156495 0.10008567 0.579553710 0.3334101 0.9523327
## [2,] 0.4173557 0.79101556 0.625634338 0.6606905 0.3187979
## [3,] 0.4105918 0.98287675 0.785845023 0.7935893 0.8769312
## [4,] 0.9985219 0.95327334 0.235170613 0.0683354 0.8937314
## [5,] 0.9758934 0.84611687 0.005967645 0.8159422 0.8784766
## [6,] 0.4021767 0.17026307 0.723613777 0.1154299 0.1512538
## [7,] 0.6307474 0.07472252 0.377636231 0.9754128 0.1851939
## [8,] 0.8606898 0.34641799 0.555328812 0.7618664 0.9727579
## [9,] 0.4456597 0.20835914 0.890897703 0.4957634 0.8928336
## [10,] 0.5070331 0.67350936 0.331669628 0.8030465 0.6159905sumCuadrados=function(x){sum(x^2)} # Función que calcula la suma de cuadrados de
# los términos de un vector x
apply(A,1,sumCuadrados) # Devuelve la suma de cuadrados de cada fila de A## [1] 1.3773744 1.7294537 3.1509771 2.7645069 3.1058000 0.7505542 1.5317619 2.6958807 2.0786580
## [10] 1.8450302apply(A,2,sumCuadrados) # Devuelve la suma de cuadrados de cada columna de A## [1] 4.061631 3.878020 3.278514 4.283749 5.528084lapply(L,fun): aplica la función fun a todos los elementos de la lista L. El resultado se devuelve también en una lista.
sapply(L,fun): al igual que lapply(), aplica la función fun a todos los elementos de la lista L, pero devuelve el resultado en forma de vector o matriz
tapply(variable,factor,fun): aplica la función fun a cada uno de los grupos de datos de variable definidos por los niveles de factor.
grupo=data.frame(edad=c(12,13,12,11,13,14,15,11),sexo=c("H","M","H","H","M","H","M","H"))
tapply(grupo$edad,grupo$sexo,mean) # Edad media para cada sexo## H M
## 12.00000 13.66667R permite la programación de funciones propias. En una función tenemos 3 tipos de elementos:
mifuncion <- function(argumento1, argumento2, ...) {
cuerpo
resultado
}Las funciones también son objetos y por tanto les daremos un nombre, en este caso se llamará “mifuncion”. Debes evitar utilizar nombres que ya estén en uso en R, por ejemplo “mean”.
La última línea del código será el valor que devolverá la función.
Ejemplo1 de función:
suma <- function(x,y){
# suma de los elementos "x" e "y”
x+y
}Una vez que ejecutes este comando, busca en el area Enviroment. Debajo de las variables, encontrarás a las funciones en memoria. Deberás encontrar la función suma.
Para probar la nueva función, en la consola puedes escribir:
suma(2,3)Ejemplo2 de función:
hipotenusa<-function(cateto1, cateto2){
h<-sqrt(cateto1^2+cateto2^2)
list(cateto1=cateto1,cateto2=cateto2,hipotenusa=h)
}Es recomendable programar las funciones en un archivo .r y, cuando se los necesita, cargarlo en memoria con el comando:
source('misFunciones.R')Tarea: - definir una función que devuelva el valor absoluto de un entero.