
R es una herramienta muy potente a la hora de hablar de gráficos. Dispone de múltiples funciones diseñadas para la creación y diseño de los mismos. Estas funciones se dividen en dos grandes grupos: funciones gráficas de alto nivel y de bajo nivel. La diferencia fundamental es que las funciones de alto nivel son las que generan gráficos completos, mientras que las de bajo nivel se limitan a añadir elementos a un gráfico existente (por tanto creado por una función de alto nivel).
Las funciones de alto nivel son aquellas que generan un gráfico completo, entre las más comunes podemos citar: plot() (gráfico de nubes de puntos, normalmente), hist() (histogramas), barplot() (gráfico de barras), boxplot() (gráfico de caja y bigote), pie() (gráfico de torta) o pers() (superficies en 3D). Estas funciones disponen de diferentes argumentos que permiten controlar distintas cualidades del gráfico, las más utilizadas son:
xlim, ylim: controlan, respectivamente, la extensión de los ejes X e Y.
xlab, ylab: especifican las etiquetas para los ejes X e Y respectivamente.
main: indica el título del gráfico.
sub: permite especificar un subtítulo.
Las funciones de bajo nivel permiten añadir líneas, puntos, etiquetas, etc. a un gráfico ya existente. Son de gran utilidad para completar un gráfico. Entre estas funciones cabe destacar:
lines(): Permite añadir lineas (uniendo puntos concretos) a una gráfica ya existente.
abline(): Añade lineas horizontales, verticales u oblicuas, indicando pendiente y ordenada.
points(): Permite añadir puntos.
legend(): Permite añadir una leyenda.
text(): Añade texto en las posiciones que se indiquen.
grid(): Añade una malla de fondo.
title(): Permite añadir un título o subtítulo.
Es de suma importancia a la hora de graficar tener una idea clara de lo que se quiere lograr. Una práctica útil para esto es formular preguntas de interés a nuestro set de datos. Un buen gráfico es aquel que revela una conclusión rica en información sobre los datos analizados.
Cuando se analizan los datos se pueden tener varios enfoques. Lo ideal es tomar un enfoque que se alinie a los objetivos a cumplir. Se puede, por ejemplo, hacer un análisis variable a variable:
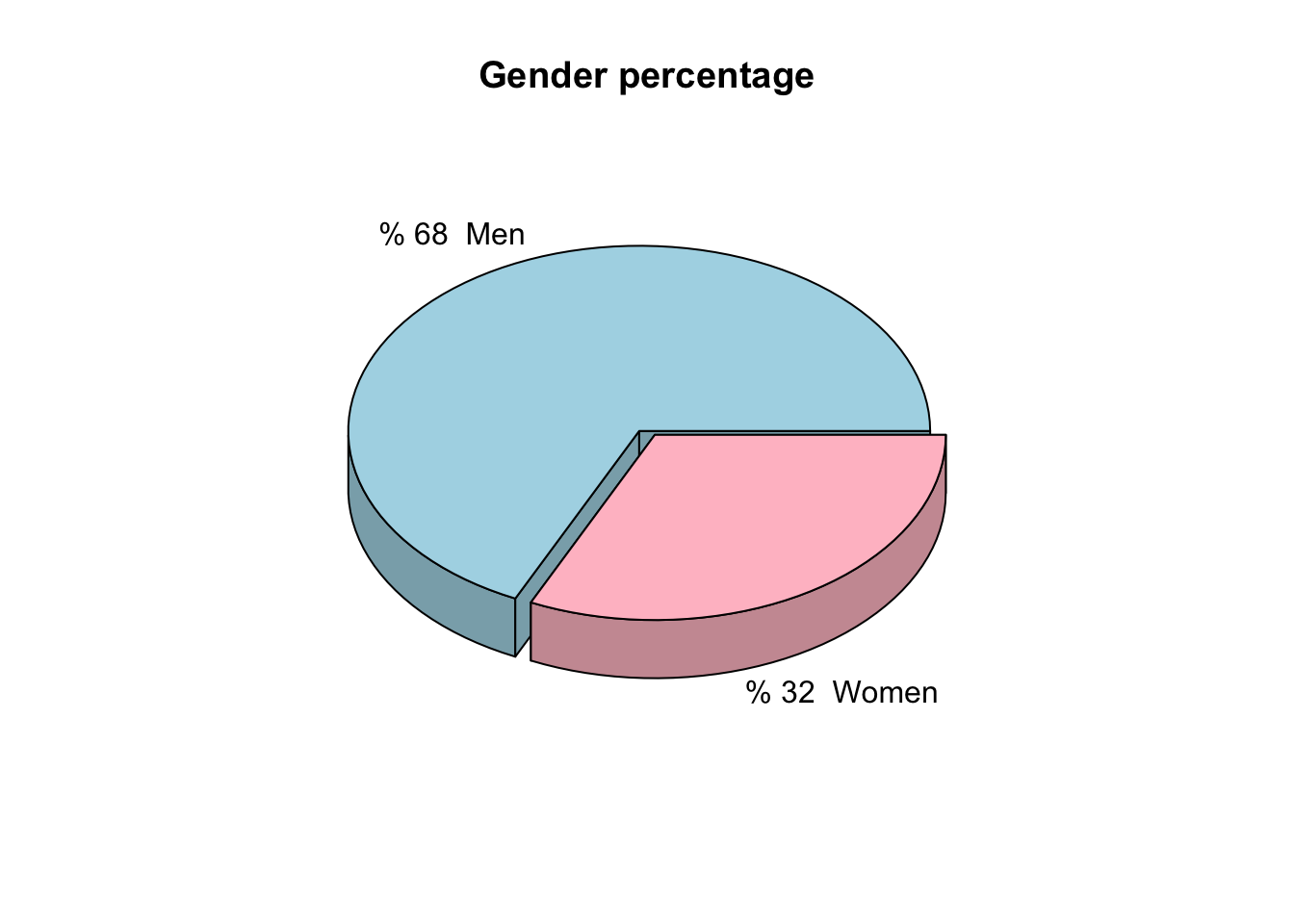
En este caso se tomó una variable (SEX) de un set de datos y se graficó el porcentaje de Hombre y Mujeres. Este gráfico, al ser de una sola variable, no permite que se extraiga información importante.
Por otro lado, si se hace un análisis un poco más “profundo”, el resultado es mejor. Se puede, por ejemplo, hacer un análisis cruzando variables:
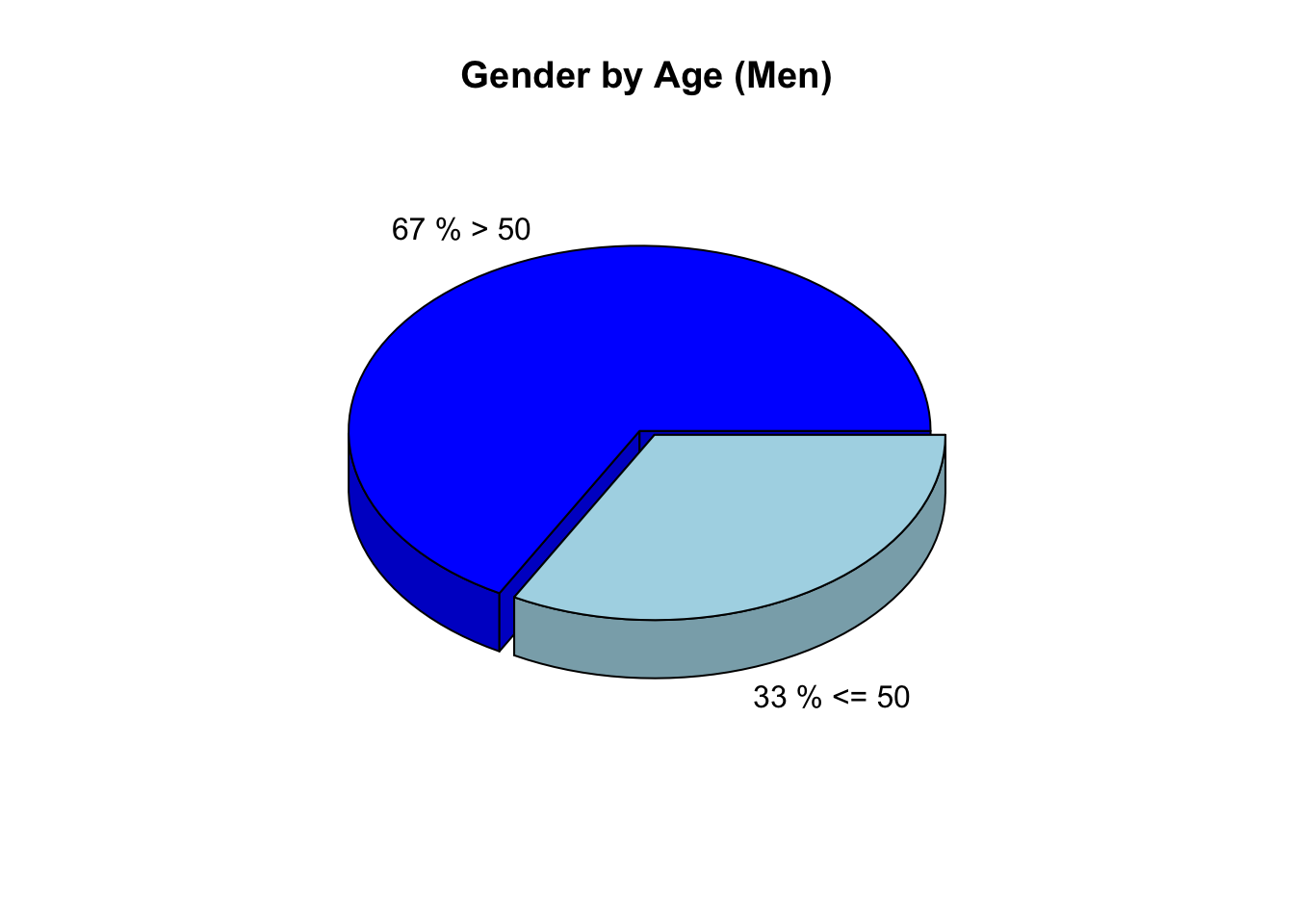
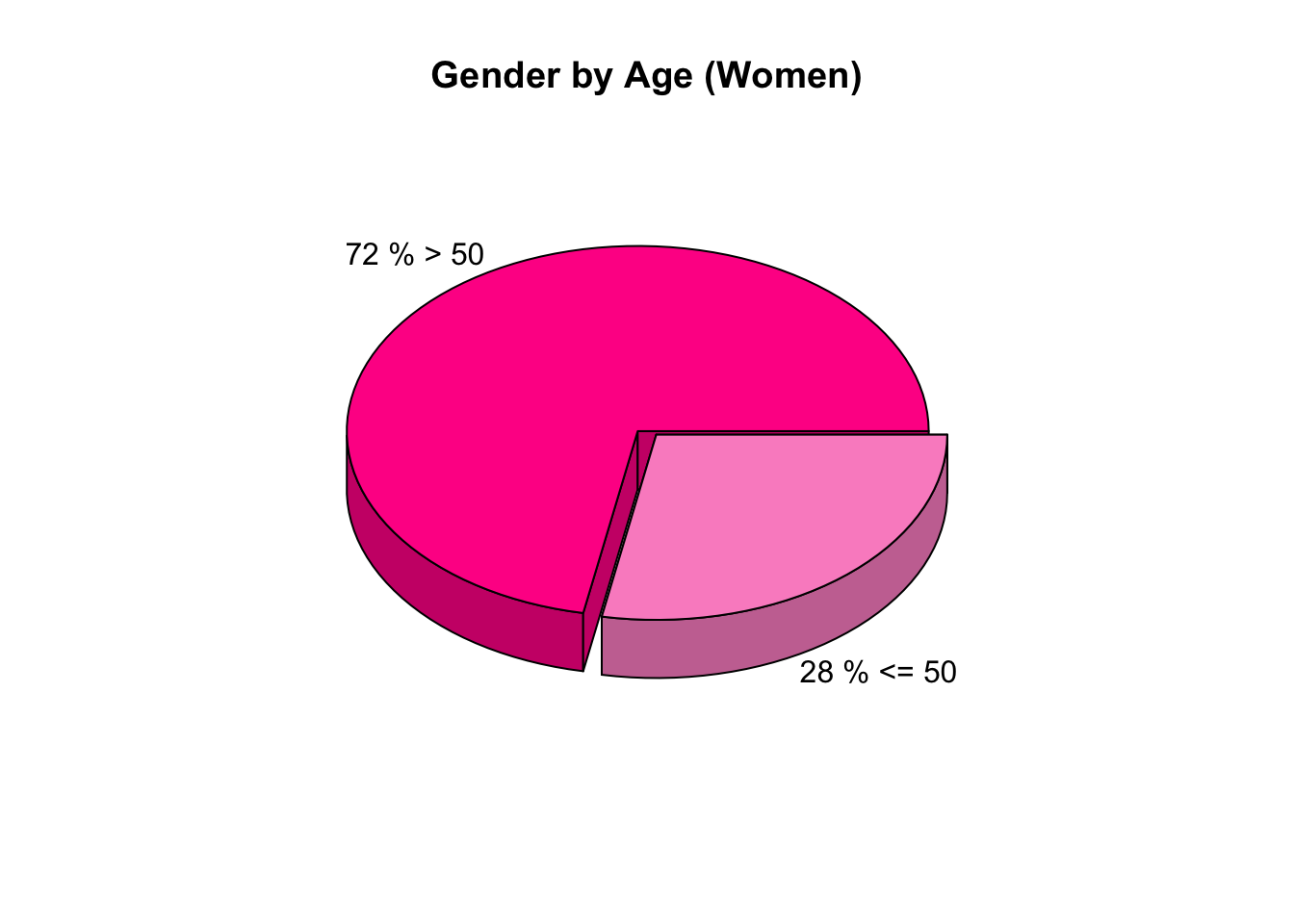
En este caso, se cruzan las variables SEX y AGE, obteniendo una conclusión un poco mas profunda que la anterior, y se obtiene mejor información. De más esta decir que las conclusiones que se obtienen dependen totalmente de las preguntas que se le hacen a los datos, y estas dependen del enfoque que se toma.
Algunas recomendaciones para realizar un buen gráfico son las siguientes:
Los gráficos deben mostrar información que no resulta evidente al observar el dataset y al realizar una simple operación sobre los datos.
Graficar solamente lo que no se puede decir con números o frases. Ej: puede tener poco sentido hacer un gráfico de torta para indicar el porcentaje de mujeres y de varones en un dataset. Habría que evaluar bien la justificación. Parece más razonable indicar, en una línea, 35 % mujeres / 75 % varones.
No complejizar los gráficos innecesariamente con colores y exceso de parámetros. Luego de hacer un gráfico, asegurarse que, a primera vista, se entiende la información que se quiere mostrar.
Pensar bien: el título del gráfico y los labels. Es un mal gráfico aquel que cuesta entender.
Tener cuidado con el tema “interpretación”. Nunca un data scientist toma decisiones ni saca conclusiones de los datos. Esas son tareas de los directivos que miran las gráficas. No “tomar partido” en las conclusiones. Ej. de lo que no hay que decir: “el costo de la matrícula es muy caro” o “los alumnos del colegio XXX tienen mal desempeño académico”. Hay que tener en cuenta que, los que reciben los datos pueden ser responsables o causantes de los mismos.
Un buen gráfico suele tener la capacidad de cruzar información o integrarla (Ejemplo: Scatterplot Interactivo, sección 7.2)
No hay que abusar de los gráficos ni de los paquetes que ofrecen opciones muy ricas en lo visual. Primero hay que plantear la necesidad y sólo graficar lo que realmente haga falta.
En los siguientes links podrán encontrar diferentes tipos de gráficos y especificaciones de su código con sus parámetros y como customizarlos.
R Graph Gallery: https://www.r-graph-gallery.com/
Plotly for interactive graphs: https://plot.ly/r/
Paquetes utilizados para la creación de los gráficos (algunos vienen con R, otros es necesario descargarlos):
library(plotrix)
library(ggridges)
library(ggplot2)
library(treemap)
library(dplyr)
library(babynames)
library(maps)
library(geosphere)
library(plotly)
library(gapminder)
library(gganimate)A continuación se hace una categorización de los graficos más comunes y sencillos de realizar. Para cada uno de ellos se muestra el código que los genera y el display. Los paquetes utilizados para la creación de los mismos se listan a continuación. El más importante es ggplot2, el resto de ellos son para ediciones de dataframes, o bien, algunos sets de datos. (Importar “Heart_Disease” y cambiar su columna SEX y CPT a factor).
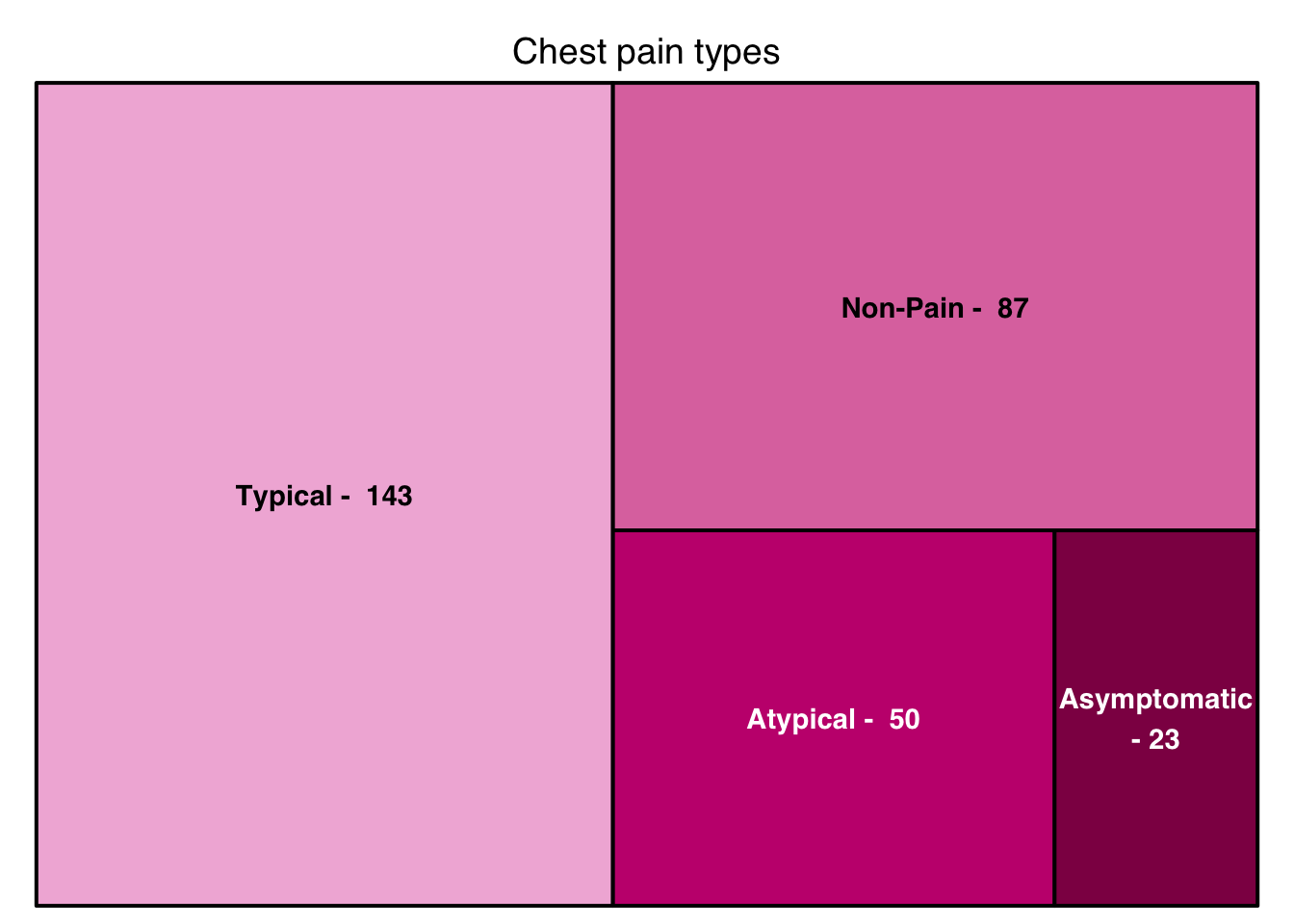
Son gráficos utilizados para mostrar proporciones o partes de un conjunto de datos diferenciandolas por ciertas características.
Un gráfico circular o “gráfico de torta”, es un recurso estadístico que se utiliza para representar porcentajes y proporciones. El número de elementos comparados dentro de una gráfica circular suele ser de más de cuatro. Se utilizan en aquellos casos donde interesa no solamente mostrar el número de veces que se dan una característica o atributo de manera tabular sino más bien de manera gráfica, de tal manera que se pueda visualizar mejor la proporción en que aparece esa característica respecto del total.
man <- Heart_Disease[Heart_Disease$SEX=="1",]
more50 <- round(sum(man$AGE>50)/length(man$AGE)*100)
less50 <- round(sum(man$AGE<=50)/length(man$AGE)*100)
pie3D(c(more50,less50),main = "Gender by Age (Men)", labels = c(paste(more50,"%"),paste(less50,"%")),col = c("blue","lightblue"),labelcex = 1, explode = 0.05, theta = 1, mar = c(5,5,5,5))
legend(.3,1.2,c("AGE > 50","AGE <= 50"),fill = c("blue","lightblue"))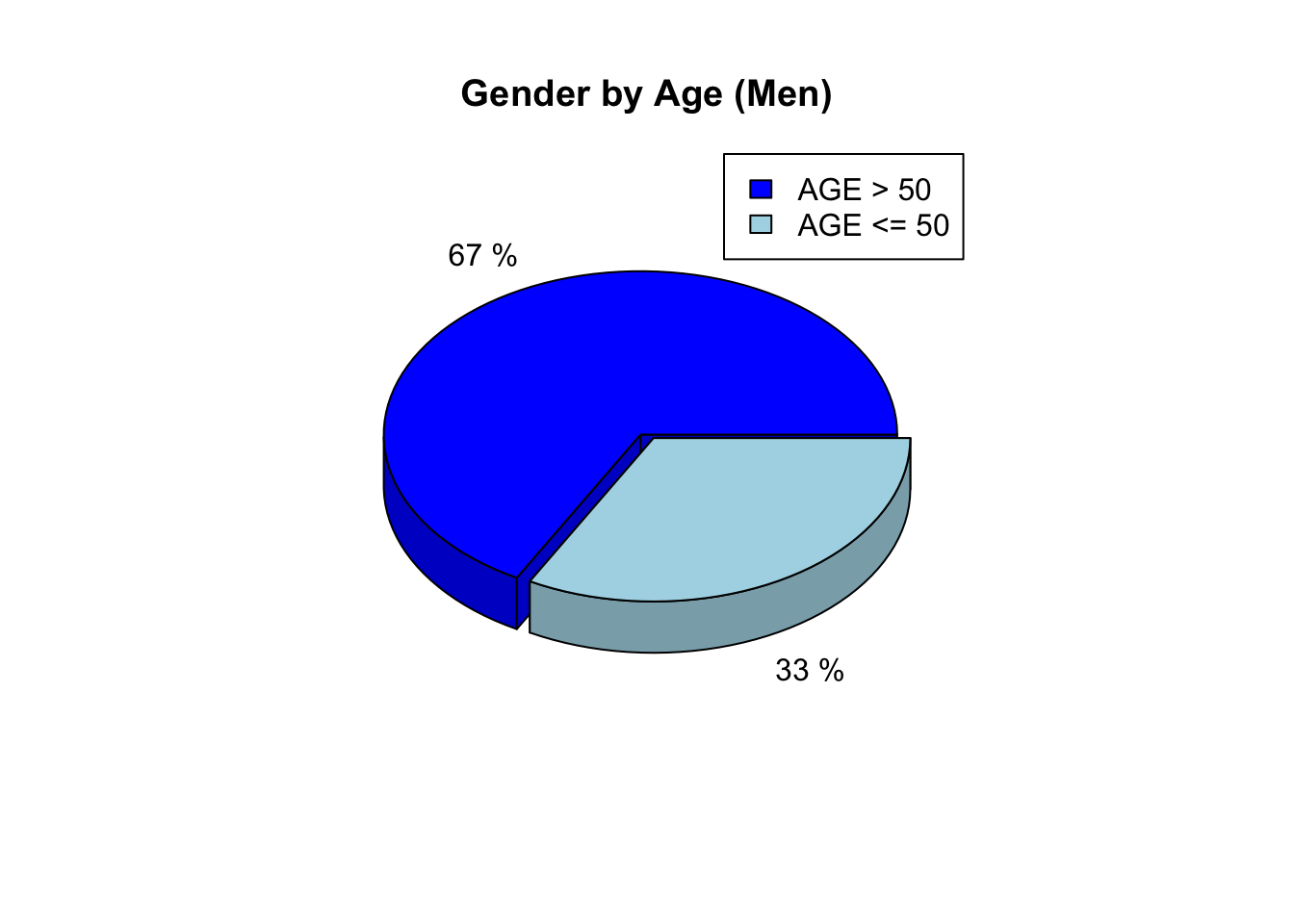
Como el piechart, pero de manera recatangular.
value <- c(sum(Heart_Disease$CPT=="0"),sum(Heart_Disease$CPT=="1"),sum(Heart_Disease$CPT=="2"),
sum(Heart_Disease$CPT=="3"))
group <- c(paste("Typical - ",value[1]),paste("Atypical - ",value[2]),
paste("Non-Pain - ",value[3]),paste("Asymptomatic - ",value[4]))
data <- data.frame(group,value)
treemap(data,
index="group",
palette = "PiYG",
title = "Chest pain types",
vSize="value",
type="index",
border.lwds = c(2,2)
)
Lista o relación ordenada de cosas o personas con arreglo a un criterio determinado.
Un gráfico de barras es una forma de resumir un conjunto de datos por categorías. Muestra los datos usando varias barras de la misma anchura, cada una de las cuales representa una categoría concreta. La altura de cada barra es proporcional a una agregación específica (por ejemplo, la suma de los valores de la categoría que representa).
ggplot(Heart_Disease, aes(x=CPT, fill=CPT )) +
geom_bar( ) +
scale_fill_brewer(palette = "PRGn",labels = c("Typical","Atypical","Non-Pain","Asymptomatic")) +
theme(legend.position="top")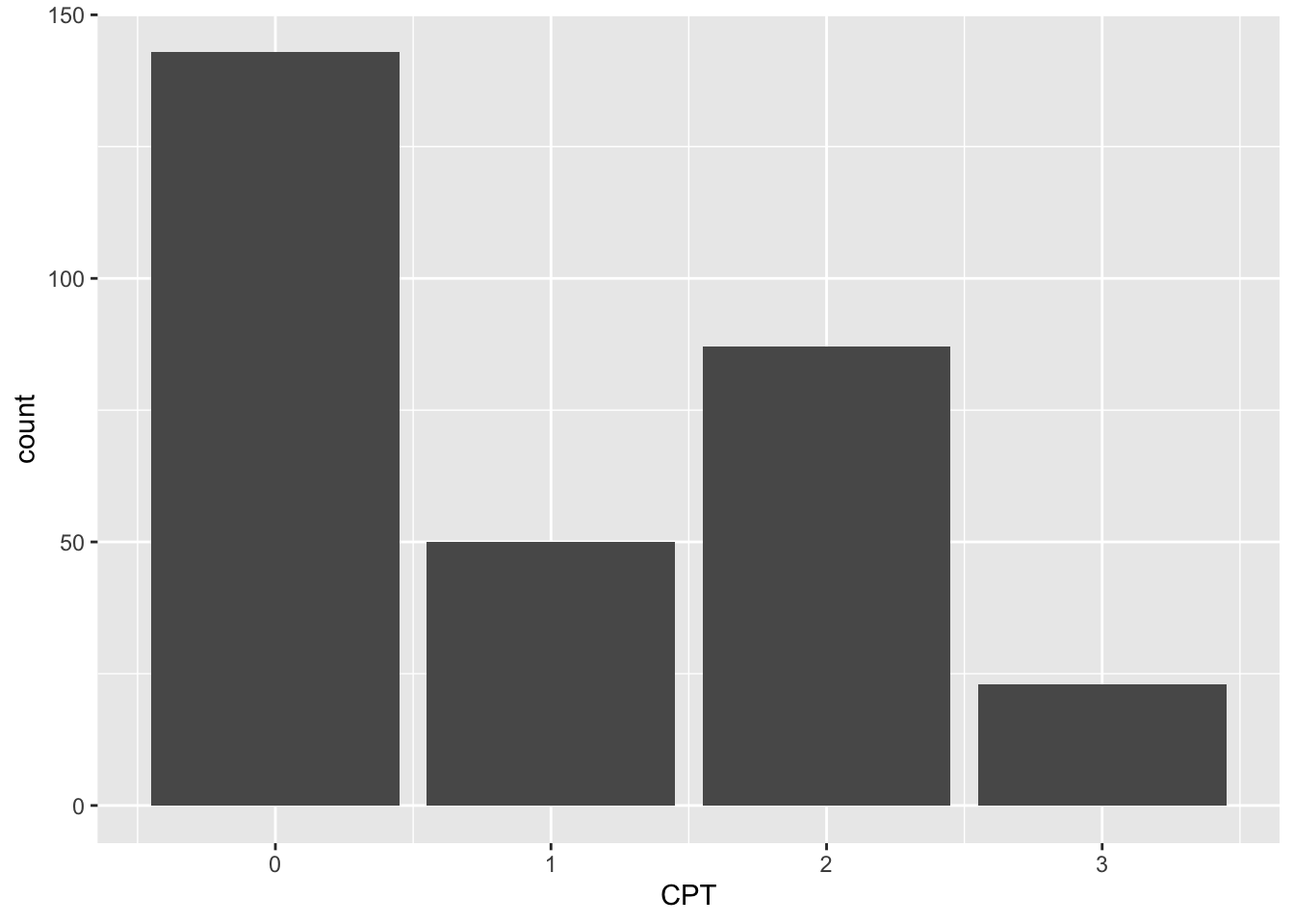
Como el gráfico de barras, pero con más variables y en vez de barras, se hace uso de “lollipops”.
y <- c(mean(Heart_Disease$RBP[Heart_Disease$CPT=="0"]),mean(Heart_Disease$RBP[Heart_Disease$CPT=="1"]),
mean(Heart_Disease$RBP[Heart_Disease$CPT=="2"]),mean(Heart_Disease$RBP[Heart_Disease$CPT=="3"]))
x <- c("Typical","Atypical","Non-Pain","Asymptomatic")
data <- data.frame(x,y)
ggplot(data, aes(x=x, y=y)) +
geom_point(color = "blue", size = 5, fill = alpha("skyblue", 0.3),
alpha = 0.7, shape = 21, stroke = 2) +
geom_segment( aes(x=x, xend=x, y=0, yend=y), color = "skyblue", size = 1, linetype = "dotdash") +
theme_bw() +
coord_flip() +
xlab("Chest pain type") +
ylab("Resting blood preassure") +
ggtitle("RBP mean by CPT")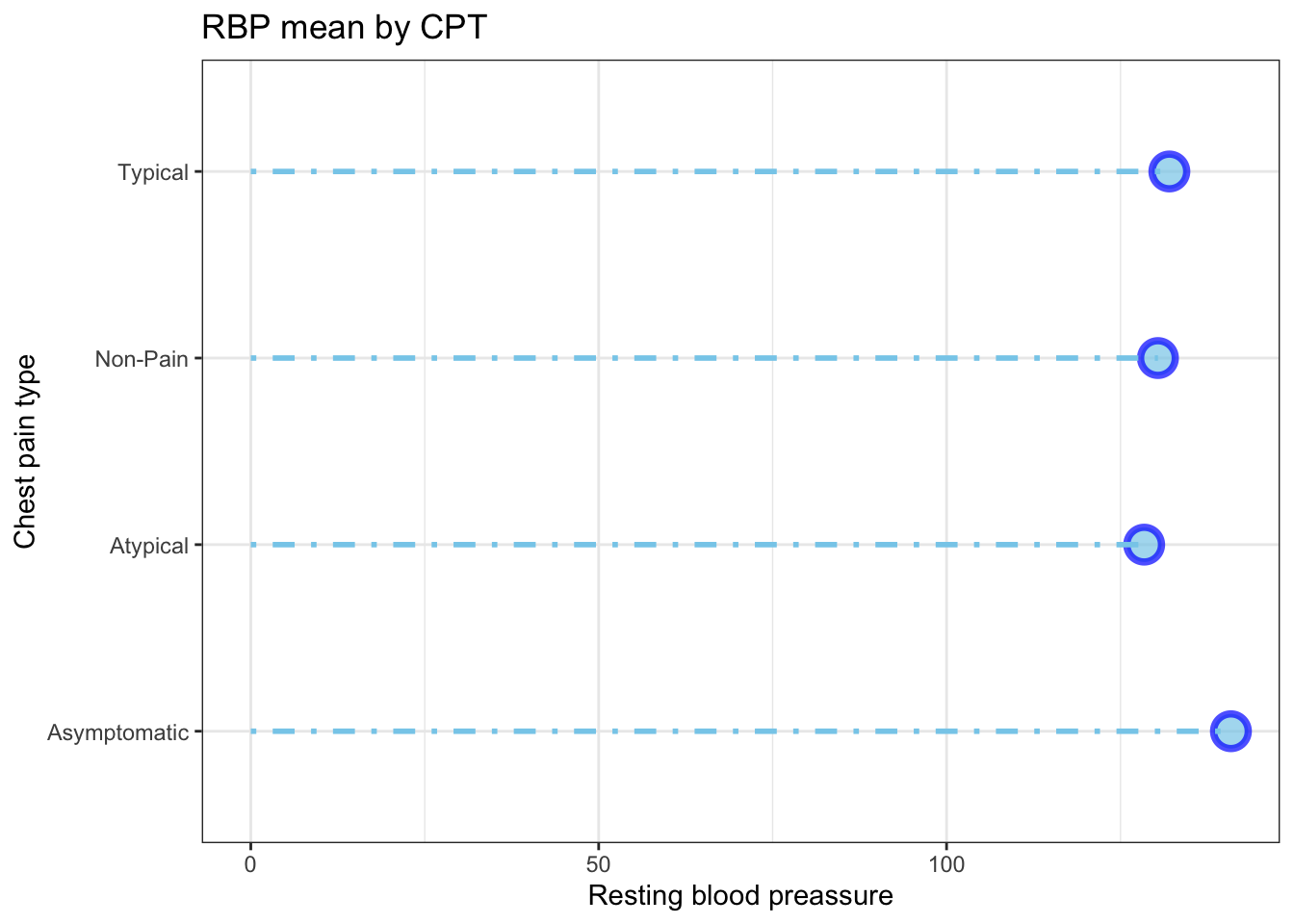
Son gráficos enfocados en mostrar la evolución de alguna característica de los elementos según el crecimiento o decrecimiento de otra variable, en genera el tiempo.
Un gráfico de líneas es un tipo de gráfico que muestra información como una serie de puntos de datos llamados ‘marcadores’ conectados por segmentos de línea recta. Es un tipo básico de gráfico común en muchos campos. Es similar a un diagrama de dispersión, excepto que los puntos de medición están ordenados (generalmente por su valor del eje x) y unidos con segmentos de línea recta. A menudo se usa un gráfico de líneas para visualizar una tendencia en los datos a través de intervalos de tiempo, una serie de tiempo, por lo que la línea a menudo se dibuja cronológicamente. En estos casos se conocen como gráficos de ejecución.
data <- babynames %>%
filter(name %in% c("Ashley", "Patricia", "Helen")) %>%
filter(sex=="F")
data %>%
ggplot( aes(x=year, y=n, group=name, color=name)) +
geom_line(lwd = 1) +
theme_grey() +
ggtitle("Evolution of baby names usage")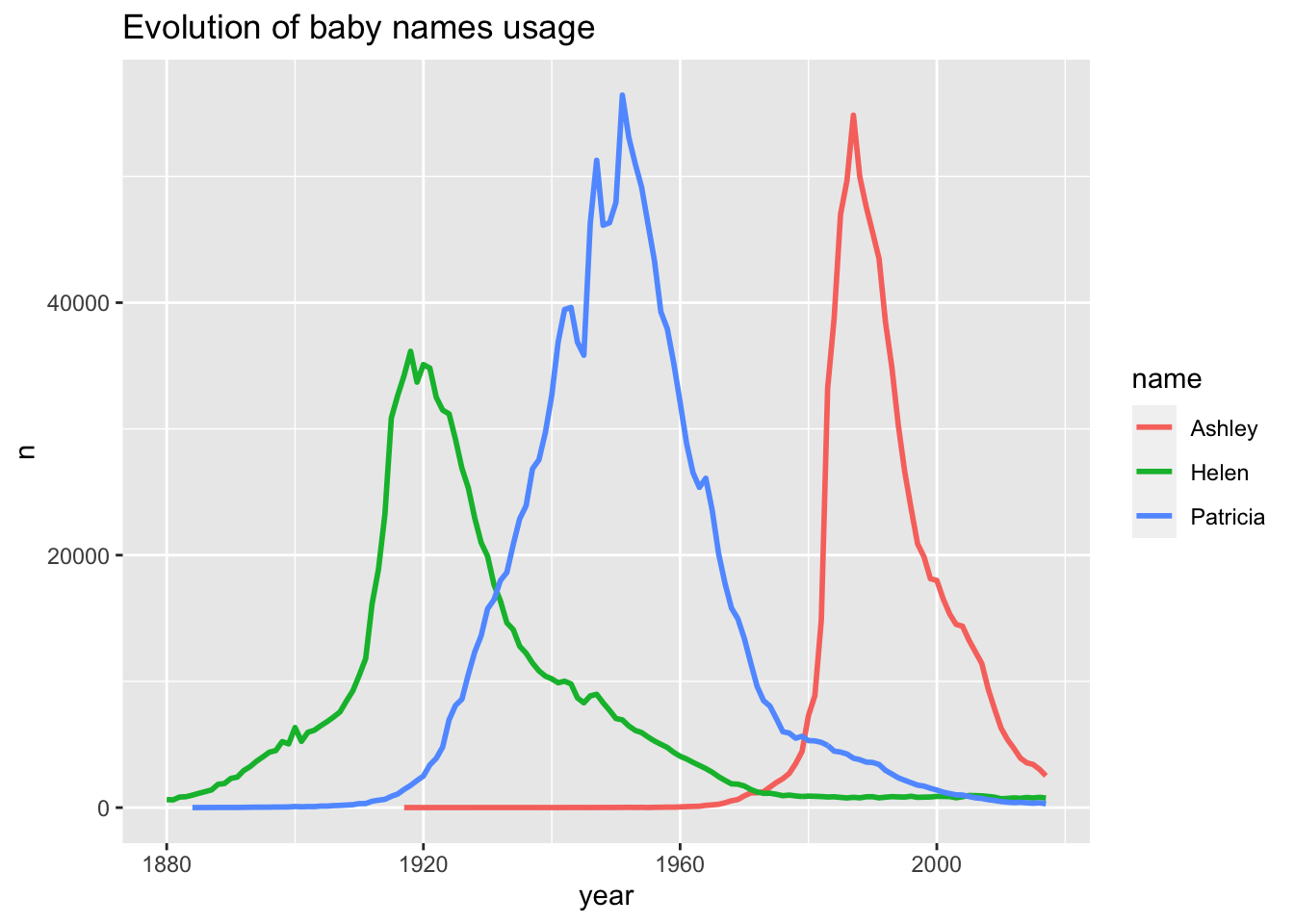
Son gráficos que se utilizan para observar como se distribuyen las variables del conjunto de datos en los elementos que lo forman. Ejemplo: Como se comporta la variable SC (Serum cholesterol) en la población analizada en el dataset Heart Disease? (ver el histograma siguiente)
En estadística, un histograma es una representación gráfica de una variable en forma de barras, donde la superficie de cada barra es proporcional a la frecuencia de los valores representados. Sirven para obtener una “primera vista” general, o panorama, de la distribución de la población, o de la muestra, respecto a una característica, cuantitativa y continua (como la longitud o el peso). De esta manera ofrece una visión de grupo permitiendo observar una preferencia, o tendencia, por parte de la muestra o población por ubicarse hacia una determinada región de valores dentro del espectro de valores posibles (sean infinitos o no) que pueda adquirir la característica.
ggplot(Heart_Disease, aes(x=SC)) +
geom_histogram(binwidth = 10, fill = "green", colour = "black", alpha = 0.6) +
theme_dark() +
ggtitle("Serum cholesterol in mg/dl")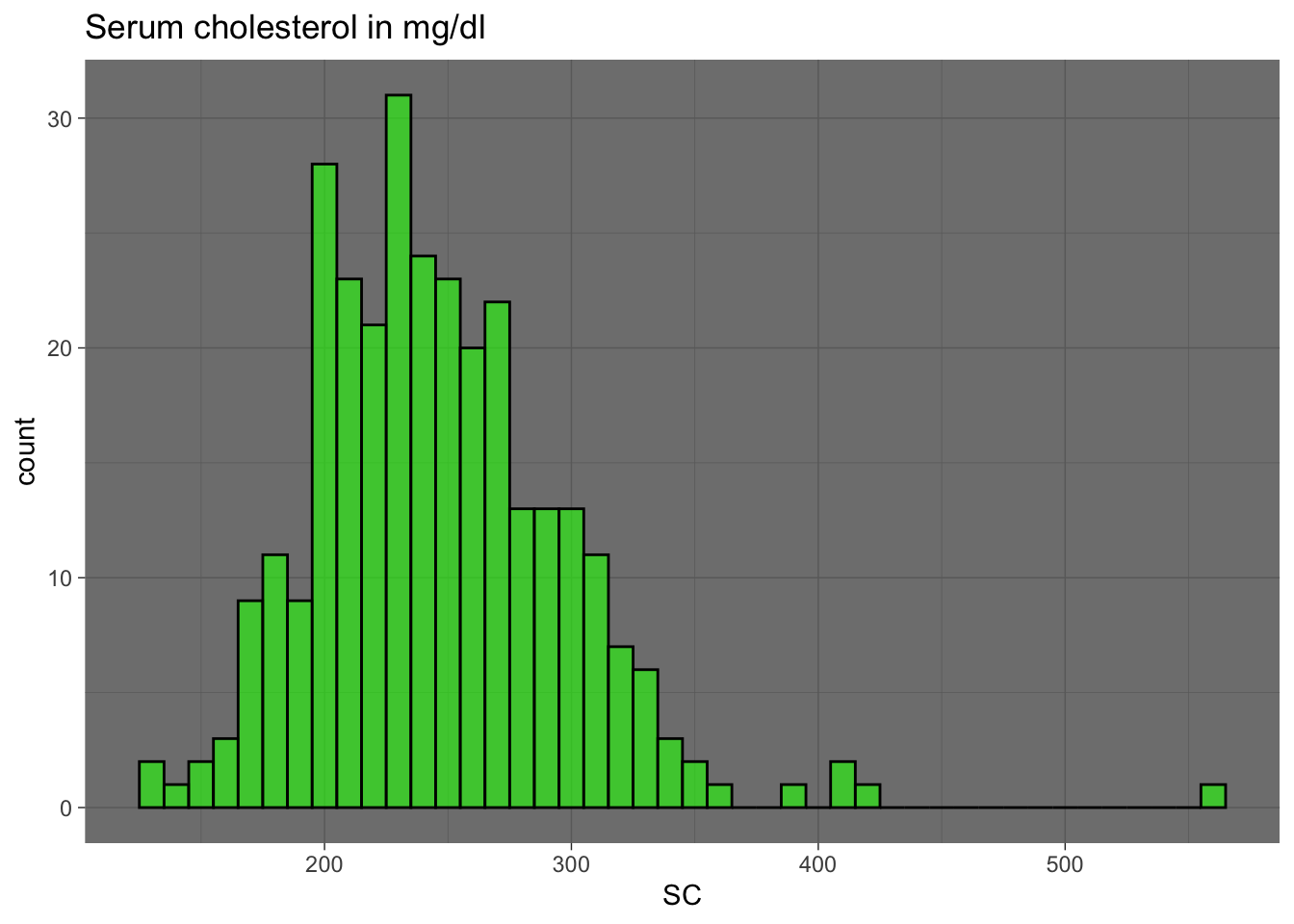
Un gráfico de densidad visualiza la distribución de datos en un intervalo o período de tiempo continuo. Este gráfico es una variación de un Histograma que usa el suavizado de cerner para trazar valores, permitiendo distribuciones más suaves al suavizar el ruido. Los picos de un gráfico de densidad ayudan a mostrar dónde los valores se concentran en el intervalo.
ggplot(Heart_Disease, aes(x = RBP, fill = SEX)) +
geom_density(alpha = 0.4) +
theme_ridges() +
scale_fill_discrete(name = "Gender", labels = c("Female","Male")) +
theme(legend.position = "top")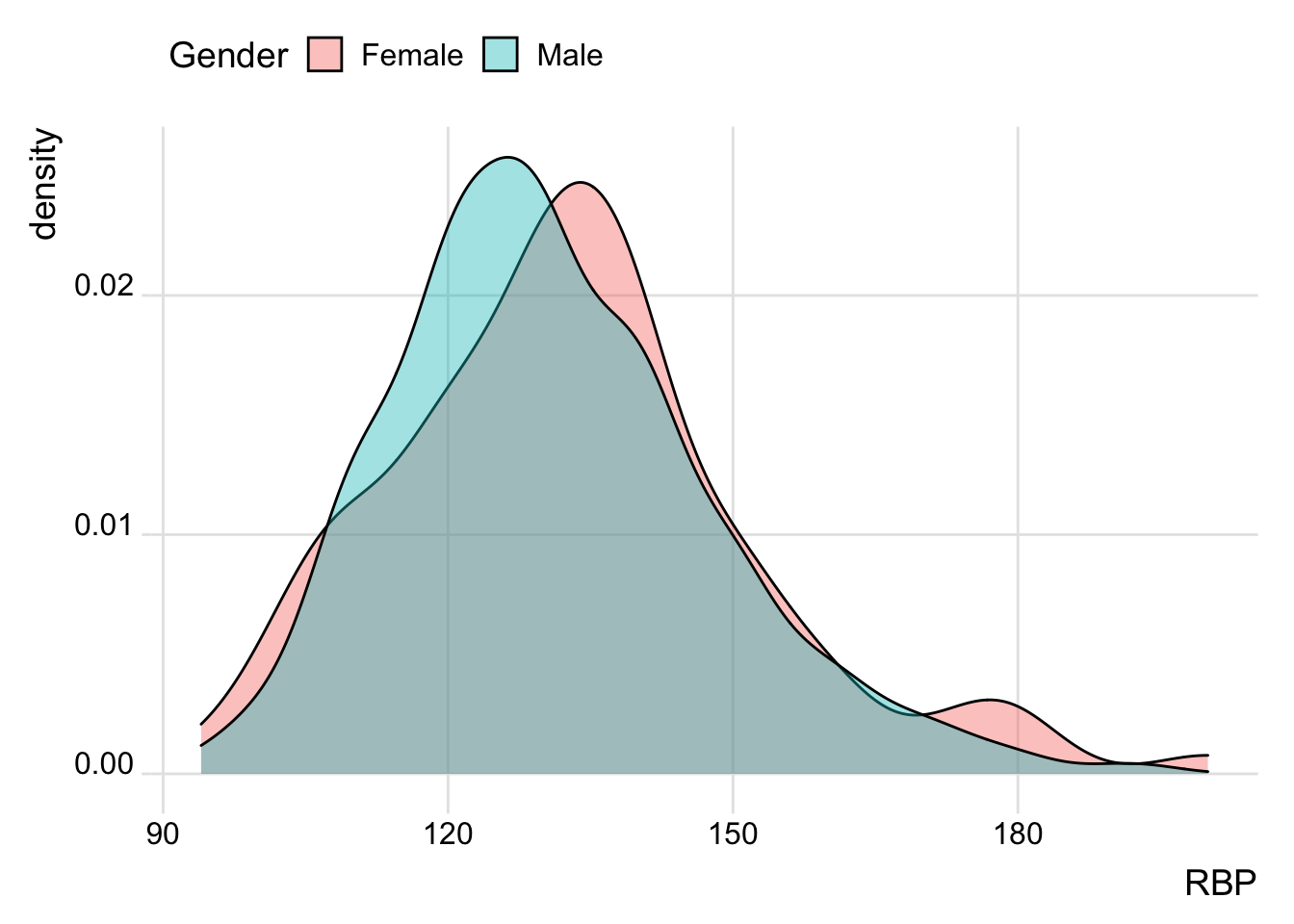
Como el gráfico de densidad, pero varios juntos.
Heart_Disease$CPT <- as.factor(Heart_Disease$CPT)
ggplot(Heart_Disease, aes(x = RBP, y = CPT, fill = CPT)) +
geom_density_ridges(alpha = 0.4) +
theme_ridges() +
scale_fill_discrete(name = "Chest Pain Type",
labels = c("Typical","Atypical","Non-Pain","Asymptomatic")) +
theme(legend.position = "top")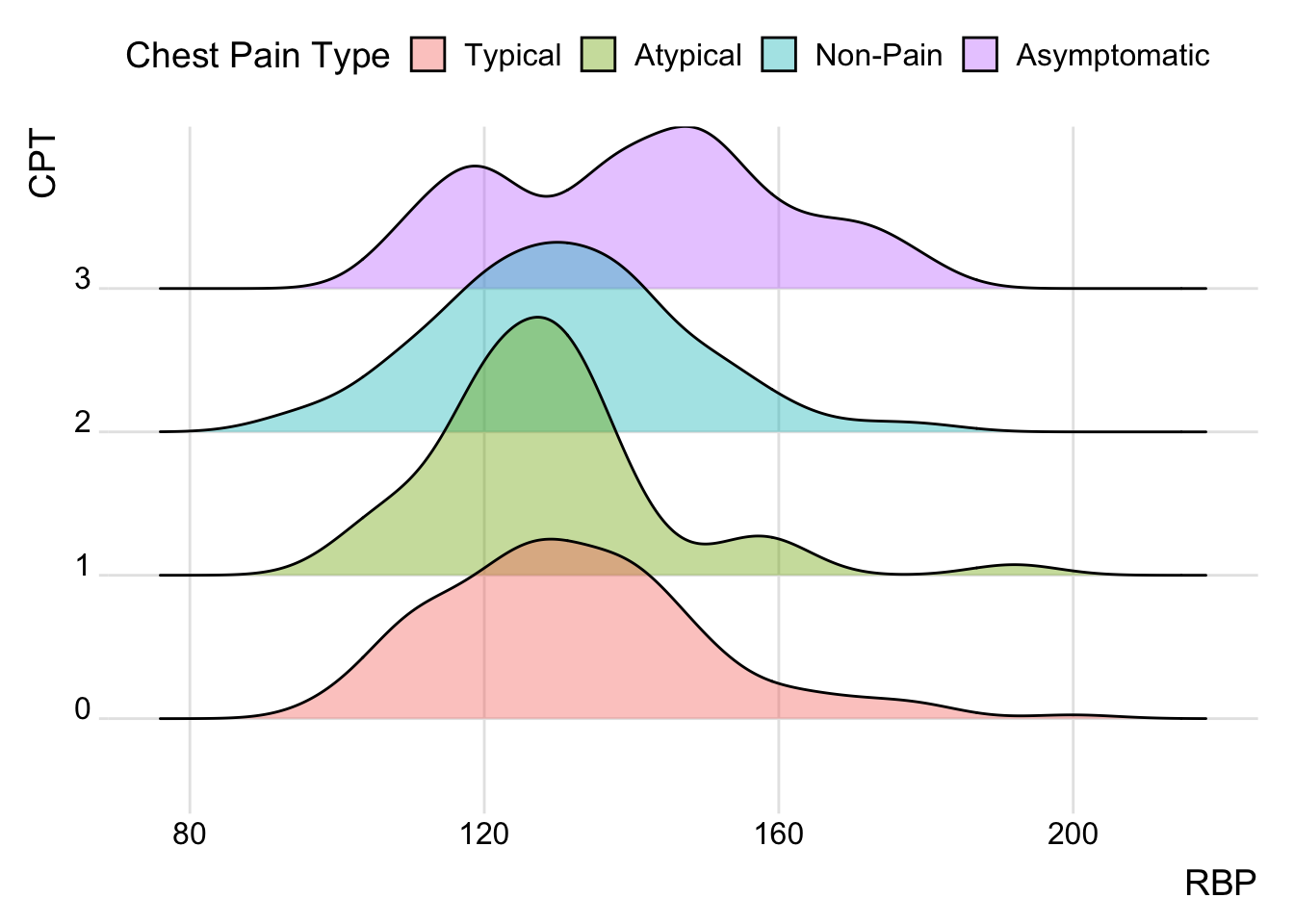
La correlación es la forma numérica en la que la estadística ha podido evaluar la relación de dos o más variables, es decir, mide la dependencia de una variable con respecto de otra variable independiente.
Un diagrama de dispersión o gráfico de dispersión es un tipo de diagrama matemático que utiliza las coordenadas cartesianas para mostrar los valores de dos variables para un conjunto de datos. Se emplea cuando una o varias variables está bajo el control del experimentador. Si existe un parámetro que se incrementa o disminuye de forma sistemática por el experimentador, se le denomina variable independiente y habitualmente se representa a lo largo del eje horizontal (eje de las abscisas). La variable medida o dependiente usualmente se representa a lo largo del eje vertical (eje de las ordenadas). Si no existe una variable dependiente, cualquier variable se puede representar en cada eje y el diagrama de dispersión mostrará el grado de correlación (no causalidad) entre las dos variables
ggplot(Heart_Disease, aes(x=AGE, y=MXR)) +
geom_point(size=3, color = "yellow", alpha = 0.4) +
theme_dark() +
ggtitle("Maximum heart rate achieved vs. Age")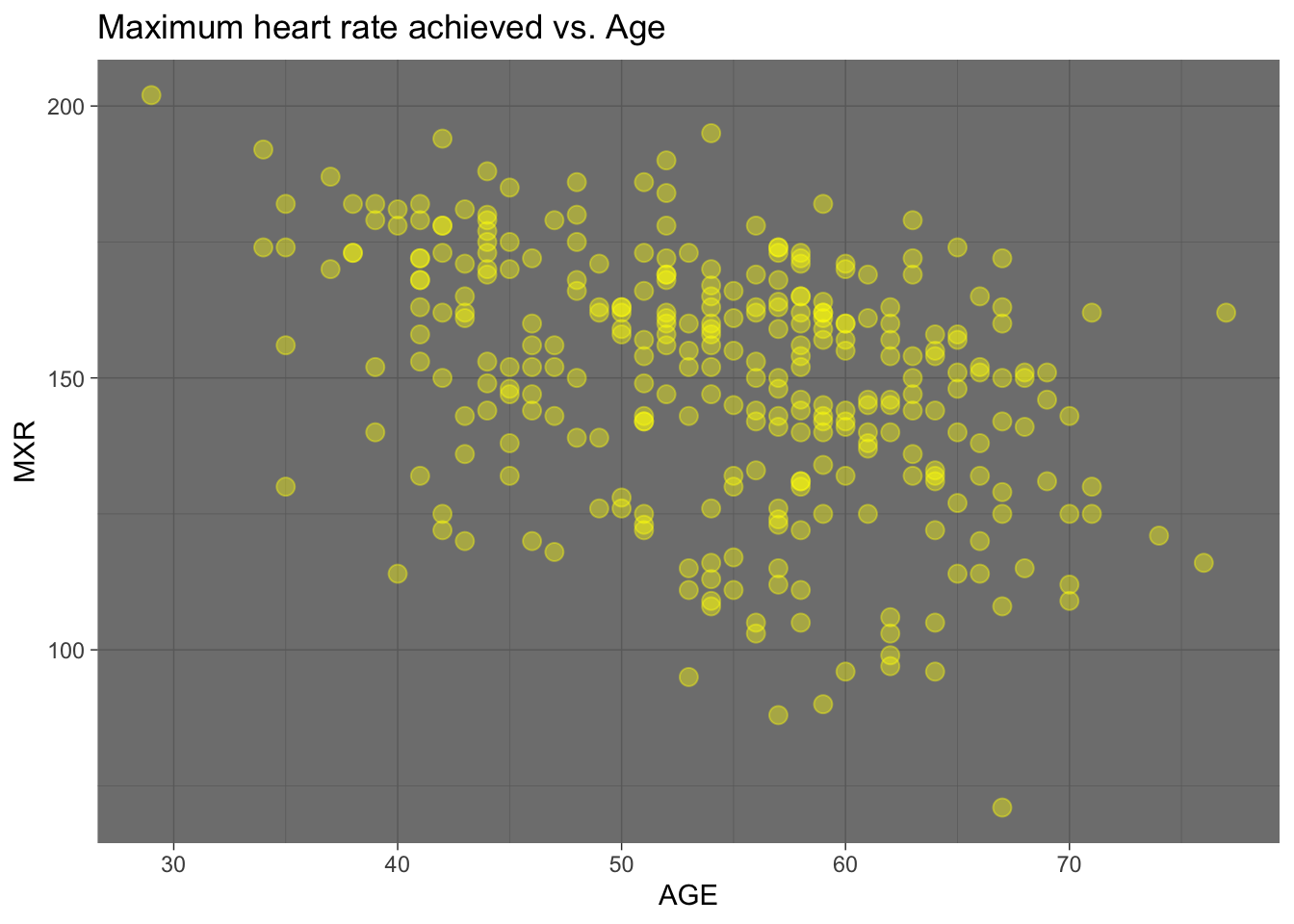
Diagrama donde se ven múltiples scatterplots cruzando las variables que se le indiquen al gráfico.
plot(Heart_Disease[,c(1,4,5,8)], pch = 20, cex = 1, col = "red")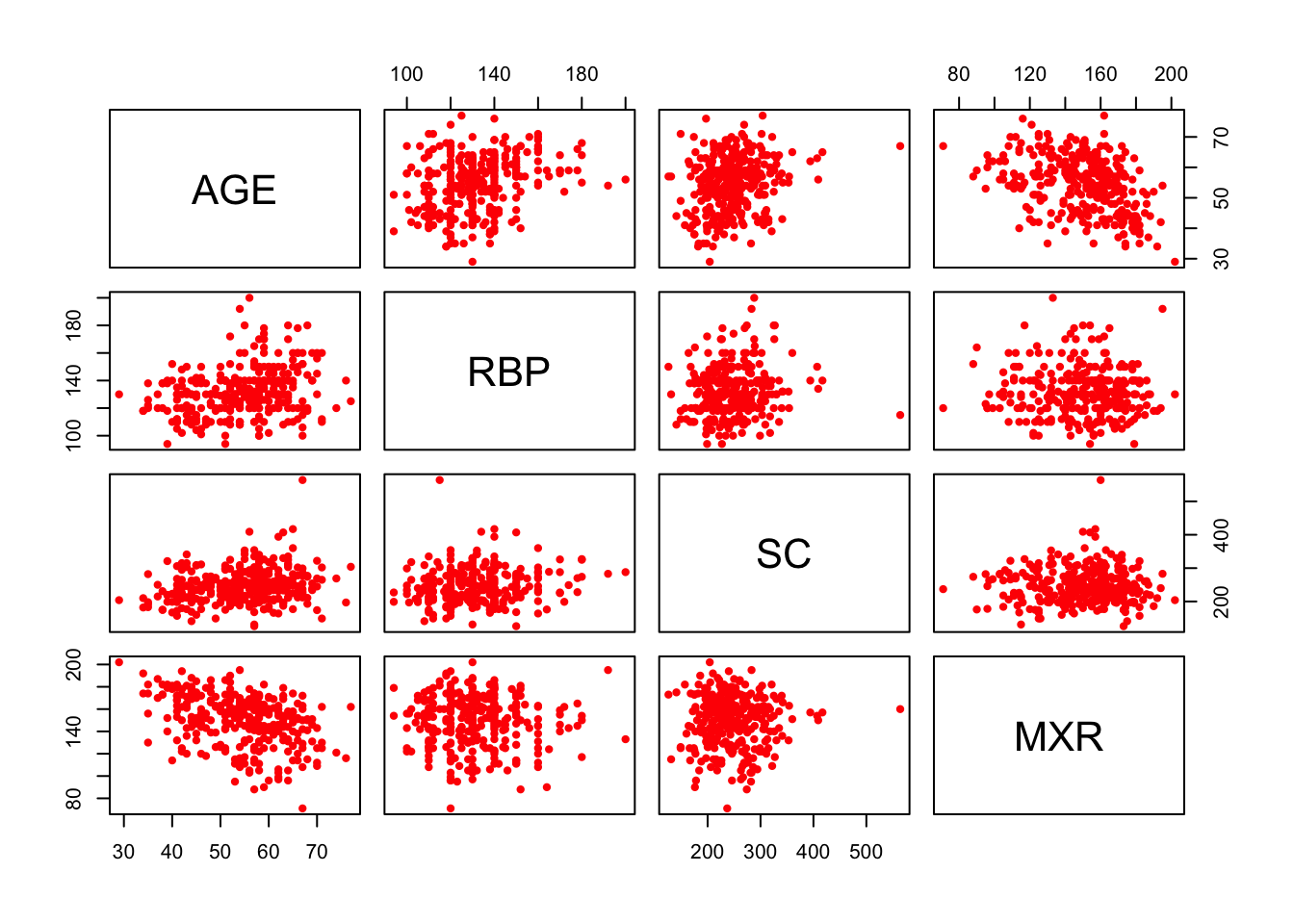
Gráficos de mapas con diversos fines, por lo general, señalar ciudades, paises, etc. en relación al set de datos.
Se utiliza para señalar puntos de interés en el mapa, y trazar conecciones en el mismo. Se detalla un paso a paso de como crearlo.
Generación del mapa
par(mar=c(0,0,0,0))
map('world',
col="#f2f2f2", fill=TRUE, bg="white", lwd=0.05,
mar=rep(0,4),border=0, ylim=c(-80,80)
)
Adición de ciudades
Buenos_aires <- c(-58,-34)
Paris <- c(2,49)
Melbourne <- c(145,-38)
data <- rbind(Buenos_aires, Paris, Melbourne) %>%
as.data.frame()
colnames(data) <- c("long","lat")
map('world',
col="#f2f2f2", fill=TRUE, bg="white", lwd=0.05,
mar=rep(0,4),border=0, ylim=c(-80,80)
)
points(x=data$long, y=data$lat, col="slateblue", cex=3, pch=20)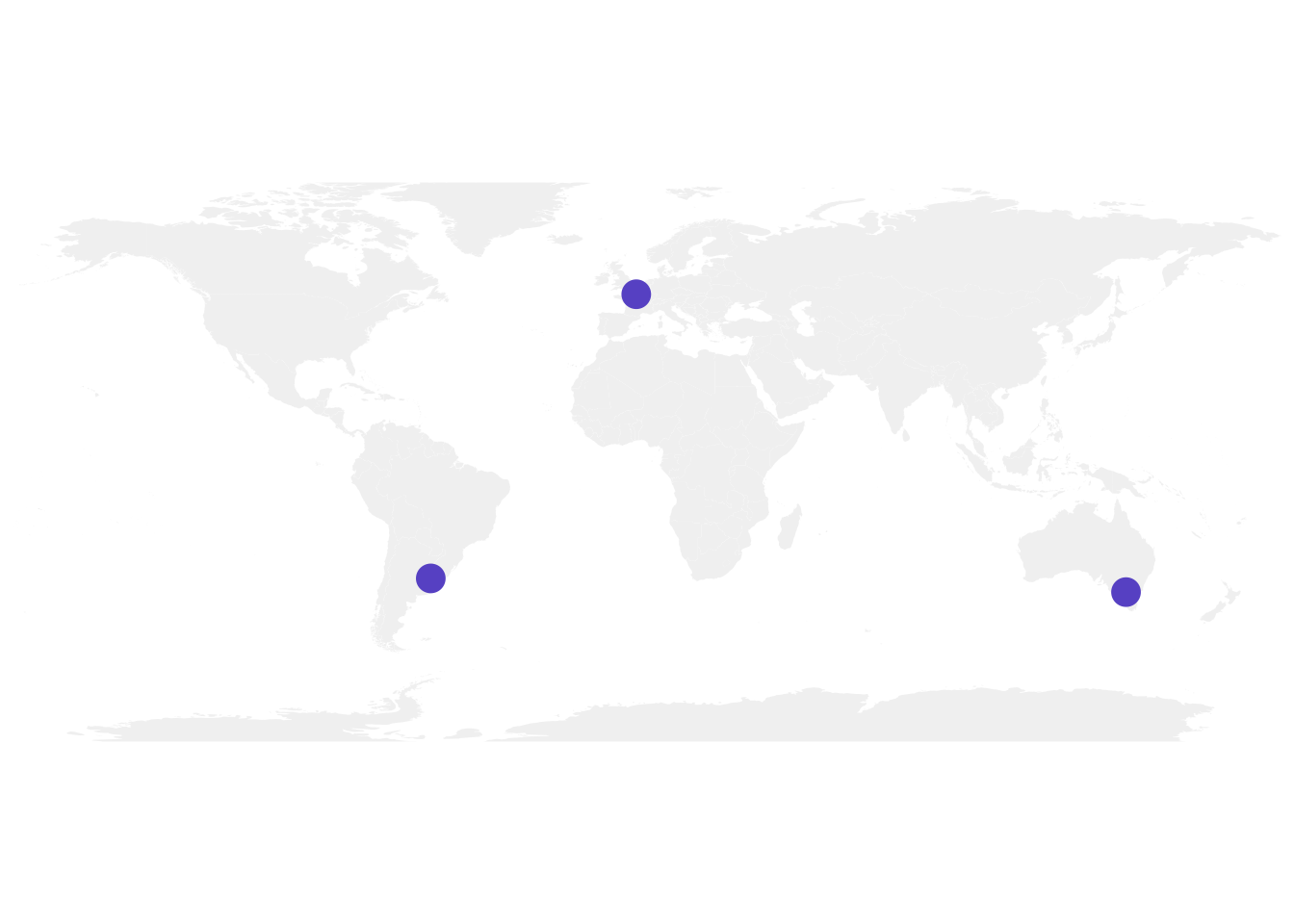
Trazado de líneas
map('world',
col="#f2f2f2", fill=TRUE, bg="white", lwd=0.05,
mar=rep(0,4),border=0, ylim=c(-80,80)
)
inter <- gcIntermediate(Paris, Buenos_aires, n=50, addStartEnd=TRUE, breakAtDateLine=F)
lines(inter, col="orange", lwd=2)
inter <- gcIntermediate(Melbourne, Paris, n=50, addStartEnd=TRUE, breakAtDateLine=F)
lines(inter, col="orange", lwd=2)
points(x=data$long, y=data$lat, col="slateblue", cex=3, pch=20)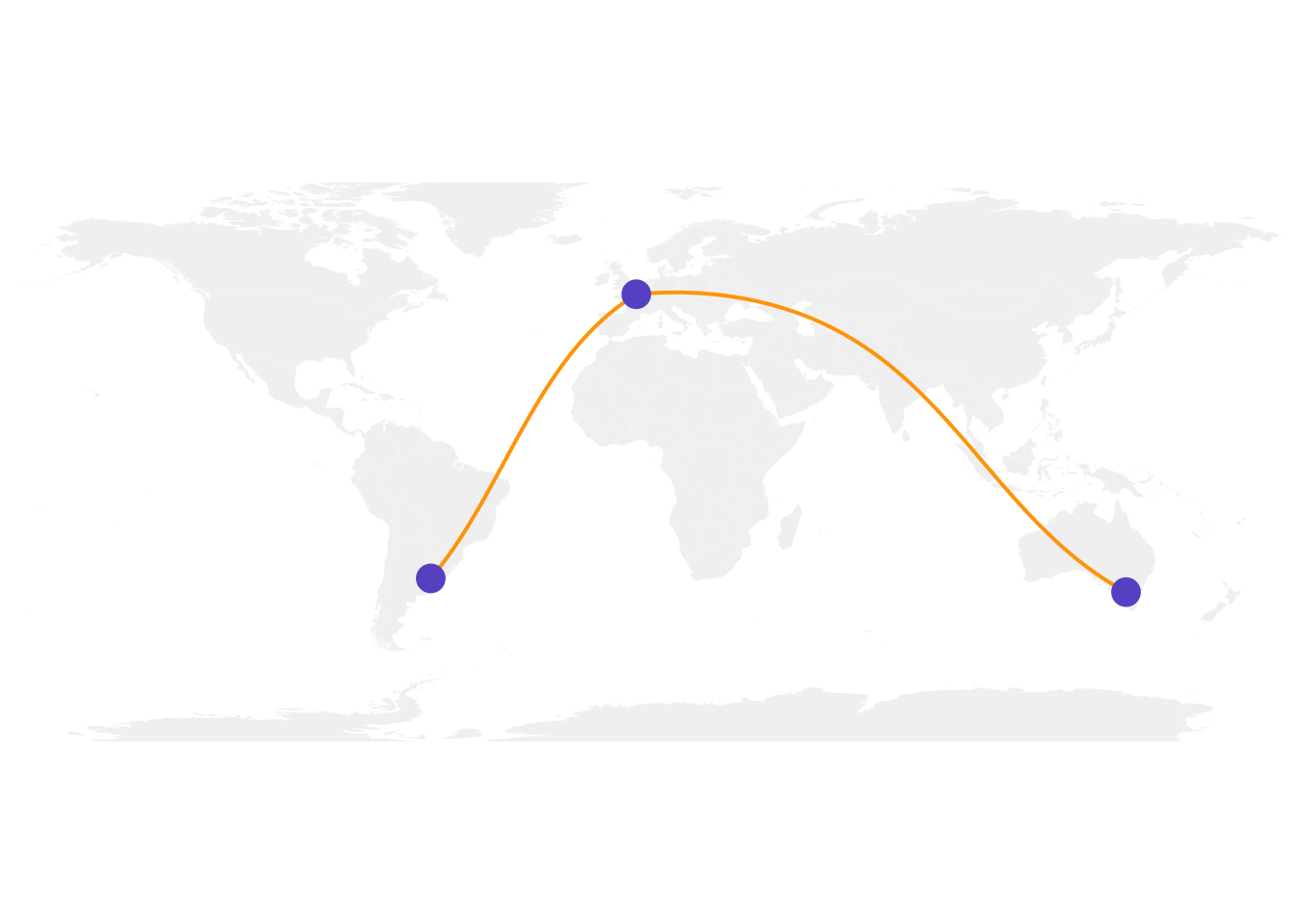
Mapa con puntos para indicar alguna característica de interés.
UK <- map_data("world") %>% filter(region=="UK")
data <- world.cities %>% filter(country.etc=="UK")
ggplot() +
geom_polygon(data = UK, aes(x=long, y = lat, group = group), fill="darkgreen", alpha=0.6) +
geom_point(data=data, aes(x=long, y=lat), color = "red", cex = 0.5) +
theme_light() +
ylim(50,59) +
coord_map() +
ggtitle("Cities at UK")
A continuación se listan algunos gráficos interactivos. Para realizar estos se utilizó principalmente el paquete plotly. Los gráficos son interactivos en sus contenidos y leyendas, se recomienda probar como se puede interactuar con los mismos.
plot_ly(
y = c(mean(Heart_Disease$RBP[Heart_Disease$CPT=="0"]),mean(Heart_Disease$RBP[Heart_Disease$CPT=="1"]),
mean(Heart_Disease$RBP[Heart_Disease$CPT=="2"]),mean(Heart_Disease$RBP[Heart_Disease$CPT=="3"])),
x = c("Typical","Atypical","Non-Pain","Asymptomatic"),
name = "RBP by CPT",
type = "bar",
marker = list(color = c("E9ADF9","F9ADBD","F9ADE3","F9C3AD"))) %>%
layout(title = "Resting blood preassure by CPT")## Warning: `arrange_()` is deprecated as of dplyr 0.7.0.
## Please use `arrange()` instead.
## See vignette('programming') for more help
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_warnings()` to see where this warning was generated.plot_ly(data = Heart_Disease, x = ~AGE, y = ~MXR, color = ~SEX, colors = c("pink","skyblue"),
marker = list(size = 8, line = list(color = "grey", width = 1))) %>%
layout(title = 'Maximum heart rate achieved')trace_0 <- rnorm(100, mean = 5)
trace_1 <- rnorm(100, mean = 0)
trace_2 <- rnorm(100, mean = -5)
x <- c(1:100)
data <- data.frame(x, trace_0, trace_1, trace_2)
plot_ly(data, x = ~x, y = ~trace_0, name = 'trace 0', type = 'scatter', mode = 'lines') %>%
add_trace(y = ~trace_1, name = 'trace 1', mode = 'lines') %>%
add_trace(y = ~trace_2, name = 'trace 2', mode = 'lines') %>%
layout(title = "Random evolutions", yaxis = list(title = "random"))USPersonalExpenditure <- data.frame("Categorie"=rownames(USPersonalExpenditure), USPersonalExpenditure)
data <- USPersonalExpenditure[,c('Categorie', 'X1960')]
plot_ly(data, labels = ~Categorie, values = ~X1960, type = 'pie') %>%
layout(title = 'United States Personal Expenditures by Categories in 1960',
xaxis = list(showgrid = FALSE, zeroline = FALSE, showticklabels = FALSE),
yaxis = list(showgrid = FALSE, zeroline = FALSE, showticklabels = FALSE))plot_ly(alpha = 0.6) %>%
add_histogram(x = ~rnorm(500)) %>%
add_histogram(x = ~rnorm(500) + 1) %>%
layout(barmode = "overlay", title = "Histogram of a normal distribution")df <- read.csv('https://raw.githubusercontent.com/plotly/datasets/master/2014_us_cities.csv')
df$q <- with(df, cut(pop, quantile(pop)))
levels(df$q) <- paste(c("1st", "2nd", "3rd", "4th", "5th"), "Quantile")
df$q <- as.ordered(df$q)
g <- list(
scope = 'usa',
projection = list(type = 'albers usa'),
showland = TRUE,
landcolor = toRGB("gray85"),
subunitwidth = 1,
countrywidth = 1,
subunitcolor = toRGB("white"),
countrycolor = toRGB("white")
)
plot_geo(df, locationmode = 'USA-states', sizes = c(1, 250)) %>%
add_markers(
x = ~lon, y = ~lat, size = ~pop, color = ~q, hoverinfo = "text",
text = ~paste(df$name, "<br />", df$pop/1e6, " million")
) %>%
layout(title = '2014 US city populations<br>(Click legend to toggle)', geo = g)Los gráficos animados son muy particulares. En general son muy útiles para mostrar la evolución de algo que se esté analizando. Es por ello que se muestran dos tipos de estos, y ambos hacen referencia a la evolución de una variable respecto a otra. Los paquetes utilizados se muestran a continuación.
ggplot(gapminder, aes(gdpPercap, lifeExp, size = pop, color = continent)) +
geom_point() +
scale_x_log10() +
theme_bw() +
labs(title = 'Year: {frame_time}', x = 'GDP per capita', y = 'life expectancy') +
transition_time(year) +
ease_aes('linear')Warning: No renderer available. Please install the gifski, av, or magick package to create animated
outputNULLdon <- babynames %>%
filter(name %in% c("Ashley", "Patricia", "Helen")) %>%
filter(sex=="F")
don %>%
ggplot( aes(x=year, y=n, group=name, color=name)) +
geom_line() +
geom_point() +
ggtitle("Popularity of American names in the previous 30 years") +
ylab("Number of babies born") +
transition_reveal(year)Warning: No renderer available. Please install the gifski, av, or magick package to create animated
outputNULL